


Meta Sells Computing Power, Palantir Slams Critics, DeepMind Emerges as Silicon Valley Leader, A New Take on AI Capital Expenditure Story

Author: Trending Beatz
The AI market experienced another violent pullback, this time because Meta hinted at potentially selling its excess AI computing power.
If this news had come out three years ago, it probably wouldn't have seemed strange. Cloud computing has always been about slicing servers and selling them to others. Amazon, Microsoft, Google have been doing this for many years. New cloud providers like CoreWeave and Nebius have also taken this path, turning NVIDIA chips into collateral to raise funds and then using those funds to acquire more chips.
However, when it comes to Meta, things take a different turn.
Meta didn't used to see computing power this way. It bought chips, built data centers, scrambled for power and land for its own models, its ad system, its recommendation streams, for the increasingly imminent superintelligence in Mark Zuckerberg's vision. It wasn't a cloud provider. It didn't used to make money by renting out machines to others.
A company that used to say, "I need as many machines as possible because the future will consume them," now says, "If these machines are temporarily idle, they can be sold to others."
This doesn't directly indicate an oversupply of computing power, but it also can't be overlooked.
On the day of the stock market plunge, Palantir CEO Alex Karp went on CNBC for an interview and ranted at the camera for nearly twenty minutes.
He was supposed to talk about Palantir's new partnership with NVIDIA, but the conversation quickly shifted to OpenAI and Anthropic's tokenomics. He mentioned that CEOs privately complain to him that the current AI adoption by enterprises is "footing the bill for tokens that create no value and also having to give up their data." He even referred to the increasingly expensive model bills as a wealth tax on companies.

For the past two years, the discussion has been about who dares to spend, who spends the fastest, and who can quickly stack up data centers. Now the questions are slowly changing. After buying the machines, who can keep them running at full capacity.
Meta's proposal has not yet materialized into a formal business. According to public reports, it has an internal initiative called Meta Compute, which may sell raw computing power. It could also, like Amazon's Bedrock, offer different models on its infrastructure to developers. Zuckerberg mentioned at a shareholder meeting that external companies come almost every week asking if they can buy their API services or purchase some compute power, and they are willing to pay prices higher than Meta's costs.
He then added a remark. They haven't done so yet because Meta believes they still need this computing power.
If they need it, renting it out is optional. If they don't need it, renting it out becomes a painkiller for the balance sheet.
The most challenging part lies here. Meta may just be creating a window in its development pace to sell temporarily idle resources. It may also be telling investors that AI expenditures in the hundreds of billions cannot always rely on a distant superintelligence and must first find a closer revenue stream.
Both of these arguments hold water.
Demand has not disappeared, only the player has changed
Capex is at the core of the AI narrative, without a doubt. Similar to the abundance seen in 2021, the expectation for Capex is continuous growth – the more water is released, the higher all branches of the market will rise. When people saw Meta getting ready to sell computing power, many people's first reaction was that AI Capex was going to collapse. Large companies have finally admitted to overbuying, and the semiconductor feast should come to an end.
But such conclusions are too easy.
Public data does not yet support such a straightforward conclusion. AWS saw a 28% increase in revenue in the first quarter, reaching $376 billion, a rare rapid growth in recent years. Google Cloud saw an even larger increase in the first quarter, reaching $200 billion in revenue. Microsoft Azure is also running at around 40% growth.
Amazon is still talking about a capital expenditure of possibly $200 billion this year, Alphabet has raised its capital expenditure guidance for 2026 to $180 billion to $190 billion, and Meta has also raised its full-year capital expenditure to $1,250 billion to $1,450 billion.
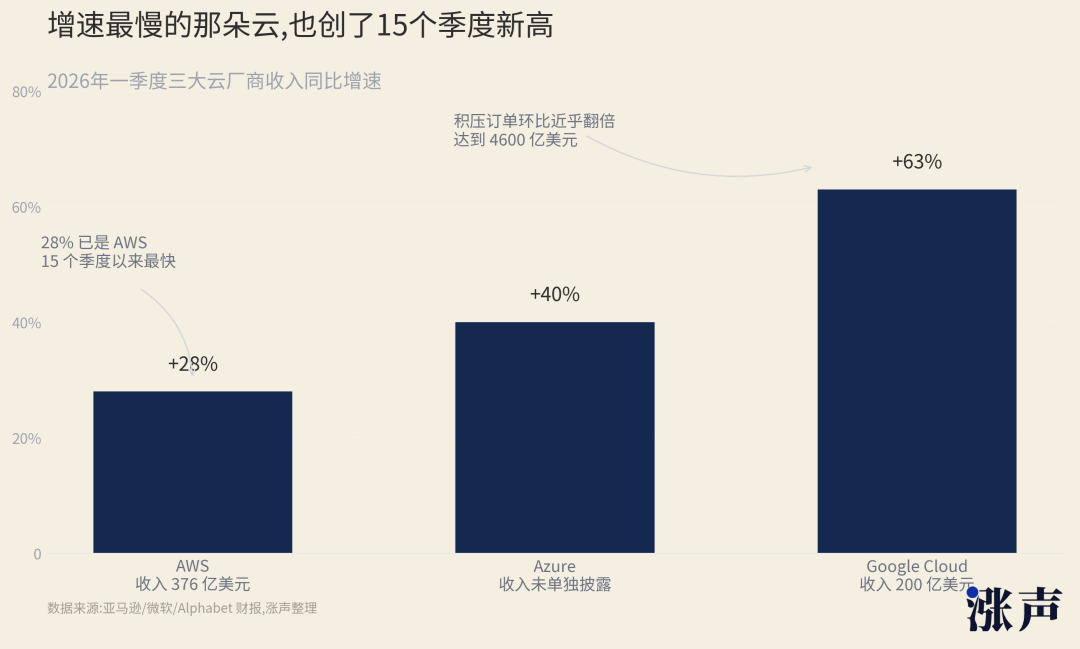
These numbers do not resemble a collapse in demand.
It looks more like a redirection.
Cloud providers' situation is different from that of model providers. Cloud providers sell the road. As long as there are people running on the road, regardless of who made the cars, they can still make money. OpenAI, Anthropic, enterprise customers, government customers, startups – they all ultimately need to land in a certain data center, on a certain type of chip, on a certain network, and on a certain electricity contract.
That's why the top three cloud providers can continue to be aggressive.
AWS even raised the price of an AI cloud service at the end of June, which is a service for customers to reserve GPUs in advance. AWS increased the price of this service starting in July by about 20%. It had already raised the price in January by approximately 15%. This is not an action taken during weak demand.
In times of scarcity, sellers raise prices.
However, not all model companies can enjoy this luxury.
Model companies need to be more selective with their assets. Computational power doesn't generate revenue by just sitting there. It needs to be continually filled with smarter models, higher frequency users, and more expensive enterprise workflows. Only when the model is good enough will users be willing to endure queues, limits, price increases, and increasingly complex subscription tiers.
This is also why Anthropic is seen by the market as a different kind of company. It's not because it's cheap, but because users are willing to entrust expensive tasks to it. Tasks such as coding, system improvements, running long tasks, and integrating with enterprise workflows, once they truly enter a production environment, consume way more tokens than casual chatting.
The trouble with a strong model is that there's not enough machine capacity.
The trouble with a weak model is that nobody cares about the machine.
Both of these troubles are called computational power, but they are not the same thing.
The xAI track has a similar taste. Grok hasn't formed a clear corporate mindset like the most powerful models have, but some computational power from the Musk system can flow to Anthropic. This action is colder than any slogan. The machine doesn't recognize the founder; it only recognizes who can fully utilize it.
The relationship between Google and Meta also shows that things are not so simple. In June, there was news that Google restricted Meta's use of Gemini because Meta wanted to purchase computational power beyond what Google could provide, even affecting some of Meta's internal AI projects. One company is considering selling computational power, yet struggles to find sufficient top-tier model capacity for certain tasks.
This is not surplus in the traditional sense.
This is a mismatch. Because the bills are starting to become glaring.
Cloud providers can continue to raise prices because what they sell is certainty. Customers want a GPU they can count on for a period of time, a stable data center, and an infrastructure that won't go down in the middle of the night.
However, once enterprise customers receive computational power, the issue is not resolved.
They still have to present this bill to the CFO. The CFO won't ask how many tokens were used; they will ask how much money these tokens have saved the company, how much they have earned, and how many mistakes they have prevented.
When it comes to the enterprise, tokens become the electricity bill
This brings us back to the beginning of that interview with Karp.
He referred to the trend of many AI companies selling to enterprises as overcommercialization. The day before the show, Palantir even posted a statement at nine o'clock on X, talking about so-called AI sovereignty, specifically addressing the tokenmaxxing model. This term is difficult to translate directly, but despite its harshness, the meaning is not complicated—it simply means treating token consumption as progress, burning money as usage, and bills as productivity.
Karp brought forward cutting-edge labs like OpenAI and Anthropic. His point was not that companies shouldn’t use the most powerful models, but rather that companies shouldn’t hand over their data, processes, and business judgment, only to then receive a larger and larger bill based on consumption.
Palantir aimed to sell a different concept. Not a generic chatbox, not a single API, but rather integrating data, approval, permissions, operational rules, and AI into the same set of business systems. What customers were paying for was not “how many times AI was used,” but whether a particular production line, a set of risk management processes, or a government task had truly been transformed.
The people in enterprises who truly manage the money have started to awaken.
Recently, UBS spoke with enterprise IT executives, and one direction became very clear. Many companies are not abandoning AI; instead, they are putting the brakes on AI spending. About 60% of the surveyed companies are restricting token expenses, adding usage barriers, especially those companies that have passed the trial period and are beginning to integrate AI into their daily operations.
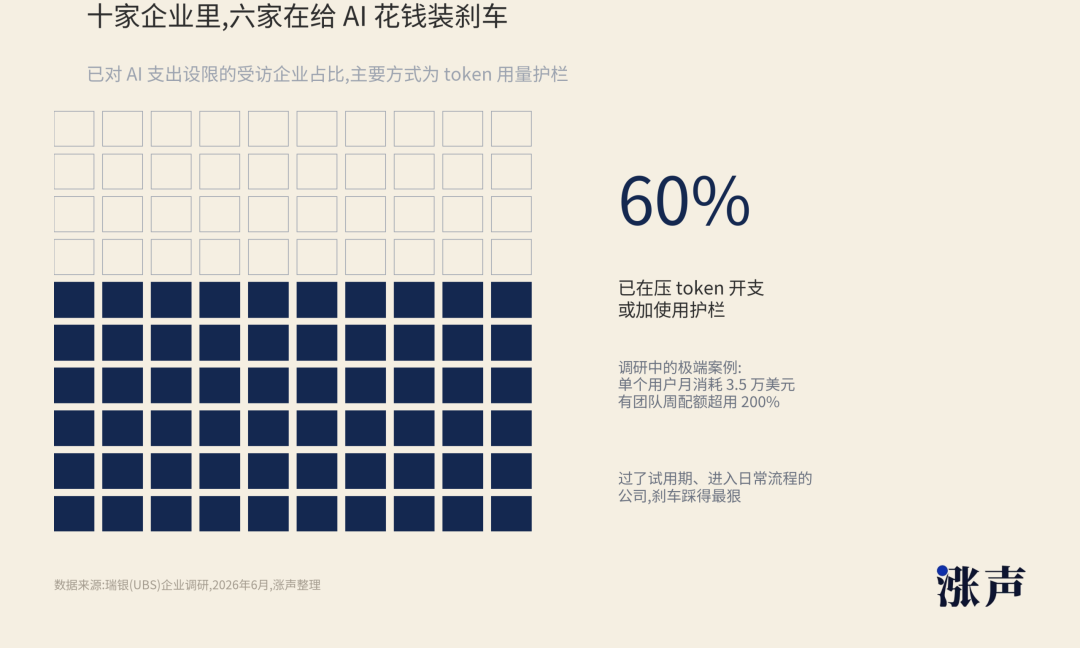
This is also a very interesting reversal.
After AI transitioned from a toy to a tool, spending became even more challenging. In the toy stage, bosses were willing to allocate budgets because everyone was afraid of missing out. In the tool stage, CFOs would inquire about how it saved hours for someone, increased sales for someone, or reduced risks for someone.
In this scenario, tokens are not like revenue.
They are more like an electricity meter.
Of course, you can say that a fast-spinning electricity meter indicates that the factory is running. You can also say that if the meter spins too quickly and the output hasn’t increased, there is an issue with the machine.
The AI agent magnifies this issue. A Codex study from OpenAI and several universities revealed some staggering data. In the first half of 2026, active Codex users increased by more than fivefold; internal token outputs for some positions at OpenAI also skyrocketed, with the median monthly token output for legal positions 13 times higher than in November 2025 and over 50 times higher for research positions.
Another study put it more starkly. The token consumption of an agentic coding task can be 1000 times higher than that of ordinary code chat and code reasoning. For the same task, token consumption between different runs may differ by up to 30 times.
This is the underlying reality of today's compute scarcity.
It's not just everyone chatting with a chatbot a bit too much.
It's software turning into a group of small workers who repeatedly read files, run commands, modify code, fail, retry, fail again, retry again. They don't have a lunch break, but every step they take consumes tokens.
When tokens become the electricity meter, whoever owns the power plant holds the power. But those who waste electricity will be questioned first.
A Thick Bill Gives a Place for Budget Models
Once the CFO starts looking at this meter, almost no further instruction is needed.
They will ask, which tasks require the strongest models, and which tasks only need sufficient models.
At this point, open-source models like GLM, Kimi, DeepSeek, and Qwen are no longer just tech news. They have become bargaining tools on the enterprise procurement table.
Even Mark Andreessen of top Silicon Valley venture capital firm a16z has said that many AI practitioners already view the smart spectrum GLM-5.2 as the first batch of Chinese models that can match or even surpass the leading U.S. public models in most tasks. This assessment may not be the final verdict, but it adds a new dimension for enterprises.
Coinbase provided a more stark example. Brian Armstrong said the company switched the default AI models to open-source models like GLM 5.2 and Kimi 2.7, implemented model routing, caching, and contextual slimming, resulting in an exponential increase in token usage but nearly halving AI expenses.
The power of this statement lies in the fact that for the first time, enterprises can disassemble model capabilities for procurement.
The most challenging tasks continue to be assigned to the most expensive models. Routine summarization, customer service, information extraction, templated code, internal knowledge base Q&A are delegated to budget models for on-premise deployment.
Open-source models may not need to win every battle.
They just need to make the procurement department believe that not every kilowatt-hour should be paid at luxury villa rates.
At this point, Meta selling compute power is no longer just a standalone piece of news.
What it and Palantir's Token-Centric Model, along with Coinbase's Open-Source Model, are talking about is the same thing: the AI spending chain is starting to unravel. The upstream sells certainty, the midstream sells outcomes, and the downstream squeezes prices. Each layer is still growing, but each layer is starting to question whether the money is being well spent.
The Hardest Part Is Not Buying the Machine, It's Keeping the Machine Busy
For the past two years, the easiest story to tell in the AI industry has been about insufficient resources.
Not enough GPUs, not enough power, not enough data centers, not enough engineers, not enough cloud to run the models. This story was too smooth. As long as something is scarce, everyone will instinctively push forward. Secure a spot first, sign up for power first, buy chips first, set up the machines first.
When grabbing resources, people don't tend to keep a close tally.
Because the cost of being a step behind seems larger.
But Meta's announcement has brought another issue to light. After buying the machine, it doesn't automatically turn into a good deal just because it's expensive. It needs to be busy every day, have customers willing to pay, have models running at full capacity, have applications turning costs into revenue.
This is utilization.
The term utilization sounds cold, but it's actually cruel. It doesn't ask if you have a future, but rather if your machine is operating today. It doesn't care about what you said at a conference, nor does it care if you bought the most expensive GPU. It only looks at one thing: whether this money has turned into a sustainable cash flow.
Cloud providers find it relatively easy to answer this question. They sell infrastructure by nature. AWS, Google Cloud, Azure sell the roads, power, and data centers. Customers need to train models, run inferences, host applications, and in the end, everything falls on some cloud.
So they can still be tough.
Leading AI model companies also have their own answer. If the model is strong enough, users are willing to wait in line, enterprises are willing to integrate, developers are willing to adapt their workflows around it, then compute power is not just inventory, it's a bottleneck. The more machines they have, the more they can scale.
The hardest part lies in the middle layer.
They have the machines, the narrative, the model teams, and a large budget. But the model hasn’t reached the forefront, the product hasn’t become a daily habit, and developers are not willing to adapt their workflows for it. For these types of companies, compute power shifts from being a weapon to inventory; it only takes one model deployment failure or one user migration.
Inventory isn't necessarily useless.
However, inventory must be discounted, rented out, or repurposed.
This is where the starkness of Meta selling compute power comes in. It doesn't prove Meta's failure, nor does it prove the disappearance of AI demand. It simply shows the market for the first time that AI infrastructure will also encounter the same issues as a regular factory.
The factory has been built, but where are the orders?
Compute Power Has Not Disappeared, Just Started to Layer
So the best way to understand this is not as "compute power surplus."
That term is too crude.
A more accurate way to put it is that compute power has started to layer.
The top layer is still tight. The strongest models, the best cloud services, the most stable GPU clusters—there are still takers. AWS can raise its prices because certainty itself has a price. Customers are not just buying GPUs; they are buying the assurance that on a certain day, at a certain hour, a certain batch of machines will be available.
The middle layer is starting to feel awkward. It may not be bad, but it's not scarce enough. It can run models, perform inference, and be sold to external customers. However, customers will compare, negotiate prices, ask why cheaper models are not being used, why other clouds are not being utilized, and why this batch of machines must be worth this price.
The bottom layer will be gradually squeezed by open-source models and cost optimizations. Companies will not forever use the most expensive models for routine tasks. They will route, cache, compress contexts, and segment models into different tiers.
The demand is growing.
A child spends without checking the bill; an adult does. After AI enters the enterprise, it will also go through this process. In the pilot phase, everyone is afraid of missing out. In the scale-up phase, everyone starts to do the math.
After doing the math, the industry chain will no longer be as neat as it was in the early days.
Some continue to raise prices because they sell irreplaceable certainty. Some switch to selling outcomes because clients do not want to pay for consumption itself. Some are forced to lower prices because viable alternatives have appeared. Some rent out machines because idle machines are more unsightly than renting out at a low price.
When these things happen simultaneously, the industry appears contradictory.
On one side is compute scarcity.
On the other side is compute renting.
On one side is a surge in token consumption.
On the other side is enterprises cutting down on AI expenditures.
On one side, there is the trend of increasingly powerful proprietary models.
On the other side, there is the trend of open-source models becoming more affordable.
They are not contradictory. They simply indicate that AI has shifted from a narrative of quantity to a narrative of structure.
The Story of the Old Railway Will Be Told Again
In the nineteenth-century railway bubble, the railway was not fake.
Once the tracks were laid, goods would indeed move, cities would indeed grow, and time would indeed be shortened. Many of the most valuable commercial networks that came later did grow alongside those tracks.
However, this did not prevent many of the original railway builders from losing money.
They didn't lose their direction. They lost by building too early, building too much, building in places without sufficient freight or passengers, or taking on expensive loans to build a route that would take too long to break even.
The story of fiber optics in the dot-com bubble was similar. Fiber optics were not at fault. They later underpinned the entire world. The mistake lay with those ledgers that crammed decades of future demand into a few years of capital expenditure.
AI data centers may also leave behind many useful things. GPUs will depreciate, power contracts will be renegotiated, data centers will upgrade equipment, and software will become increasingly hungry for computing power. Today's seemingly exaggerated token consumption may, in a few years, seem as ordinary as streaming high-definition video.
However, assets have their own temperament.
They don't care whether you believe in the future or not. They only care if someone shows up to use them every day.
The signal Meta is sending by selling computing power is stuck right here.
It is not the endgame for AI. Nor is it the endgame for semiconductors. It's more like when the capital expenditure narrative reaches the middle, and someone opens the door for the first time, allowing outsiders to see how many machines are inside the warehouse.
Some machines will be consumed by top models.
Some machines will be rented out by cloud customers.
Some machines will become cheaper in a price war.
And some machines will quietly wait for an application that hasn't appeared yet.
Over the past two years, the market has been willing to believe that all machines will eventually meet their destiny. Now it is starting to ask, who will get there first, who won't, and who, even when they get there, won't make enough money.
Once this question arises, the story of AI changes.
It's no longer just for those who buy the machines the fastest.
It's for those who can keep the machines running.

Original Article Link
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia







