


DeepSeek's Trillion-Dollar Journey: Leveraging Open Source to Unlock a Trillion-dollar Hardware Ecosystem
Original Title: DeepSeek's 10 trillion USD grand strategy
Original Author: @bookwormengr
Translation: Peggy, BlockBeats
Editor's Note: Over the past year, discussions around DeepSeek have mostly focused on model performance, open-source strategies, and price wars. However, if we only understand DeepSeek through questions like "Will they offer subscriptions?", "Do they have multimodality?", or "Can they be used as a coding agent?", we may underestimate what it truly aims to change.
This article puts forward a more radical view: DeepSeek's goal may not necessarily be short-term monetization at the application layer, but rather a series of foundational architecture innovations to reshape the cost structure of AI training and inference, indirectly driving the formation of a new hardware ecosystem. From MoE, MLA to DSA, CSA, mHC, Engram, and further to Dual Path and TileLang, DeepSeek's technical roadmap has always revolved around a core question: How to run more powerful models with less high-end compute power in a scenario where HBM, advanced processes, packaging, and the CUDA ecosystem are all constrained.
What is most worthy of attention in the article is not "Can DeepSeek make several billion dollars through APIs or subscriptions?", but whether it is binding model capabilities, memory systems, and domestic hardware ecosystem together. KV Cache compression reduces reliance on HBM, while NAND and SSD can serve as long-term caches, LPDDR can be used for weight streaming loading and Engram storage, and TileLang attempts to weaken the CUDA moat. If these innovations continue to spread, the beneficiaries will not only be DeepSeek itself, but also storage, ASICs, GPUs, network chips, and the entire AI infrastructure chain.
Of course, the judgments in the article regarding the "10 trillion USD industry ecosystem" and "1 trillion USD valuation" still have a strong speculative color. However, it offers an important path to understand DeepSeek: Open source does not necessarily mean giving up commercialization, and low prices are not necessarily just to subsidize the market. For DeepSeek, real business may not lie at the application layer, but in helping more hardware become available and making lower-cost AI supply possible. In other words, what they sell may not be the model itself, but the feasibility of the next-generation AI infrastructure.
The original article is as follows:

Have you ever wondered how DeepSeek plans to make money, and possibly a lot of it?
It did not introduce a competitive programming subscription model like GLM, MoonShot, and MiniMax; nor did it have multimodal, audio, or video models. So far, it has not even had its own harness, which is an outer execution framework used for model invocation, tool integration, and task execution—although they have recently started recruiting for relevant positions to build this system.
Meanwhile, DeepSeek seems to have firmly stood on the side of open source for a long time, even being very willing to openly share its "secrets." Isn't that crazy? Isn't it just burning money for nothing? Are those investors preparing to invest $10 billion in it just throwing money down the drain?
Personally, I believe the opposite is true.
Next, based on what DeepSeek has done so far, I will make some observations and analyze a set of strategies it seems to be following. DeepSeek CEO Liang Wenfeng's goal may be far beyond the current model competition. Perhaps what he is aiming for is a bigger prize: DeepSeek has the opportunity to impact a $1 trillion valuation while driving the formation of a new industry with a scale of $10 trillion.

TechInAsia's coverage of DeepSeek's latest funding round
Revisiting DeepSeek's "Hero's Journey"
DeepSeek has been swimming against the tide. It did not choose to continuously release slightly stronger models and then rush to package them into directly monetizable applications, such as programming subscription plans. On January 27, 2025, I tweeted a widely circulated tweet, telling the story of what I saw as DeepSeek's "Hero's Journey." Now, this story has become even more interesting.
While others were still trying to build dense models, DeepSeek opted for the more challenging Expert Mixed Model (MoE) training.
They took a "first principles" approach, inventing a new GRPO algorithm to replace the mainstream but more costly-to-implement PPO reinforcement learning algorithm at the time.
They found that Reinforcement Learning from Verified Rewards (RLVR) was a key strategy for enhancing model reasoning capability.
They also introduced a simple inference decoding strategy through "Multi Token Prediction," making the training signal denser.
They enhanced the "ZERO bubble" pipeline to improve the utilization of limited GPU resources.
They released an expert load balancer to make it easier for everyone to deploy MoE models. Especially through the "Wide Expert Parallel" strategy, the model can serve larger batches, significantly reducing the inference cost.
They invented mechanisms such as MLA, DSA, CSA, HCA to reduce the need for KV Cache and keep the increasing computational demands as close to constant as possible as the context length grows.
They invented Engram to exchange memory for computational efficiency.
They also invented mHC, enabling stable training even as the model scales up. There are many similar examples.
In the most common narrative structure of the "Hero's Journey," the hero never decides from the outset where his journey will lead. It is through a journey of learning that he gradually discovers his true great mission and accomplishes it despite many obstacles. He will encounter many skeptics, but he chooses to ignore them. He will also encounter many malicious actors. He has obvious flaws or weaknesses, but eventually overcomes these problems to fulfill his mission. He faces seemingly insurmountable challenges but finds ways to ally and learns how to wisely use limited yet valuable resources. It is this aspect that makes the audience willing to cheer for the hero. This is also why DeepSeek has gained followers, global respect, and opponents.
As I will elaborate on next, DeepSeek has been on this journey for a long time and has gradually discovered its ultimate destiny: its goal is not to sell programming subscription services but to drive a $10 trillion China AI hardware ecosystem and achieve a $1 trillion valuation itself. In the process, it will also create opportunities for many newcomers in the Western hardware ecosystem.

Let's start with some interesting KV Cache calculations
Take a look at @SemiAnalysis_'s very timely tweet:
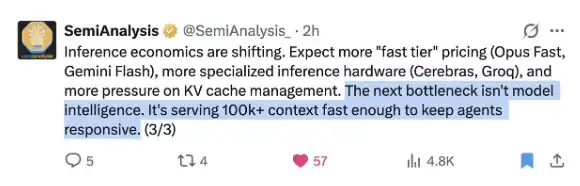
DeepSeek has solved this problem better than anyone else!
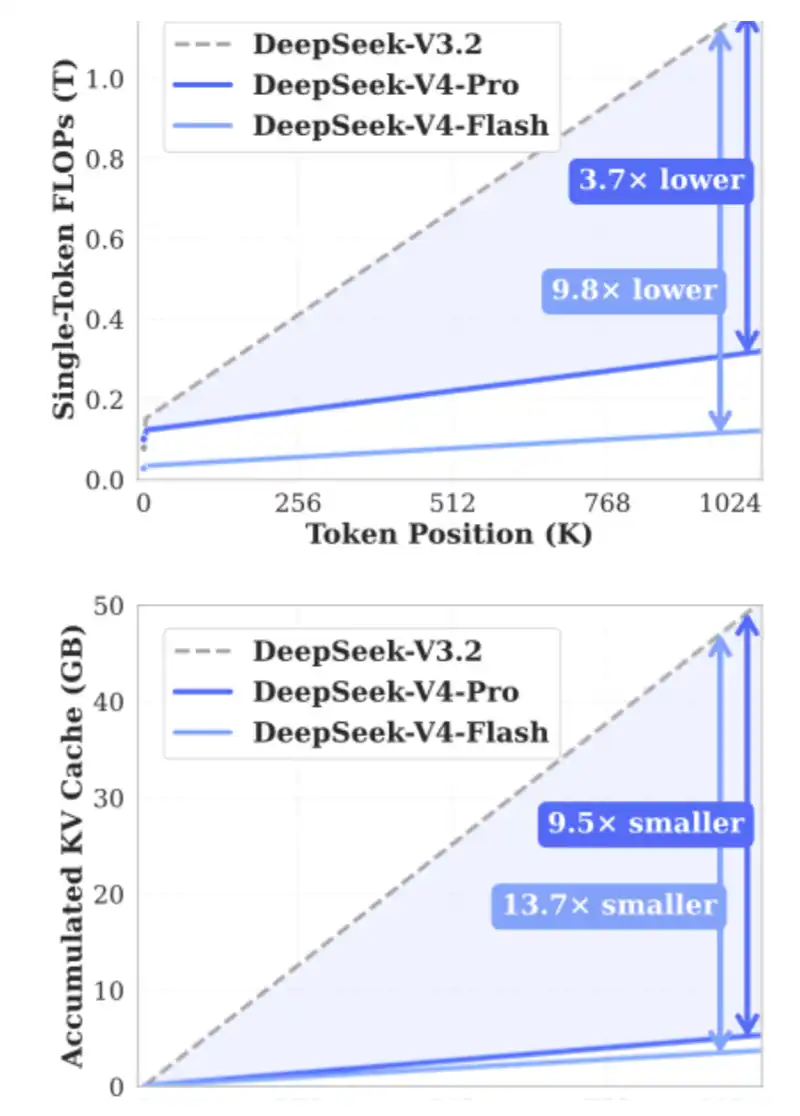
Let's start with a fun KV Cache calculation. Don't worry, even if you're not a math person, it's okay. We will use the recently released KV Cache Calculator to see how much KV Cache savings DeepSeek V4 Pro can bring and compare it to the latest GLM and Qwen models.
Here I calculate with a context length of 1 million, assuming an 8-bit KV precision and 16-bit indexer precision. You can also try this calculator yourself: https://kvcache.ai/tools/kv-cache-calculator/
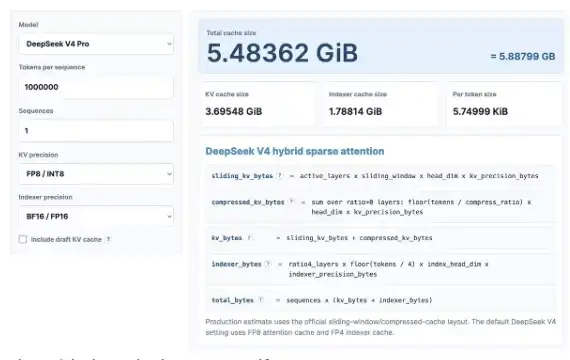
You can also try the calculator yourself!
At a context length of 1 million:
·DeepSeek V4 only needs 5.48GB of HBM;
·GLM-5 requires 60GB of HBM;
·Qwen3-235B-A22B, on the other hand, requires as much as 89GB of HBM.
Things to note:
·DeepSeek is a 16 trillion parameter model;
·GLM-5 is roughly a 700 billion parameter model and has adopted DeepSeek's MLA and DSA but has not yet used the latest compression attention mechanism;
·Qwen3-235B-A22B is approximately a 235 billion parameter model using the GQA attention mechanism.
DeepSeek has made a fundamental contribution to mitigating memory pressure. If such innovations are widely adopted, they will significantly reduce the operating costs of long-cycle agents and unlock the next wave of new application scenarios.
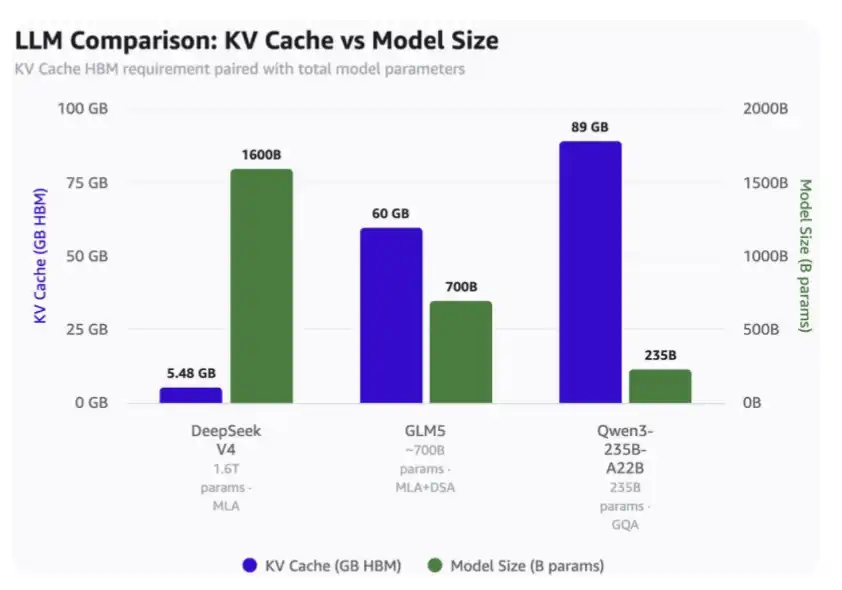
KV Cache Occupancy Comparison for 1 Million Tokens Context and Model Scale
The Methodology Behind the "Madness"
The reason why the KV Cache volume can be so small without sacrificing model quality is that DeepSeek can provide long-term caching at an extremely low cost — its cost is even less than 3% of the Sonnet 4.6 cache hit price, and DeepSeek can retain the cache for several hours.
For long-running tasks, a smaller KV Cache means it can be more economically offloaded to SSD and reloaded when needed, reducing reliance on HBM. From the perspective of the Chinese AI hardware industry, HBM is not only in short supply but also one of the most difficult-to-manufacture memory types.
In addition, DeepSeek has also developed technology to load the KV Cache faster from SSD, as described in its Dual Path paper.
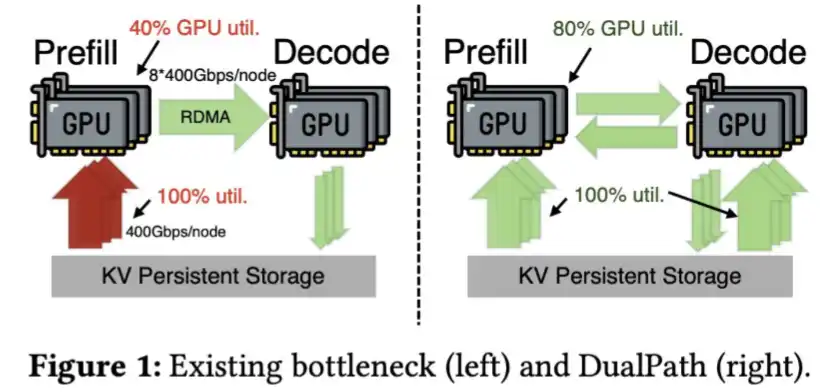
DeepSeek V4 has achieved significant compression of the KV Cache, to the point where this step may no longer be necessary.
So, who benefits most directly from KV Cache compression?
Who is the major supplier of SSDs? Let's not forget that YMTC (Yangtze Memory Technologies Co., Ltd.) is growing to become a giant in the 3D NAND field. NAND can help DeepSeek avoid redundant KV computations. In turn, DeepSeek has created a huge market for NAND and SSD—not only benefiting Yangtze Memory Technologies but also other related manufacturers.

However, this is not just about NAND and SSD.
LPDDR memory also holds great potential. It can serve as a place to store model weights and stream these weights to HBM when needed, easing the demand for HBM. The SGLang team once published a great blog post introducing this. The diagram below illustrates how this scheme works.
While DeepSeek did not specifically design for this scheme, its MoE architecture, abundant expert models, and the 4-bit weight feature make it easier to implement.
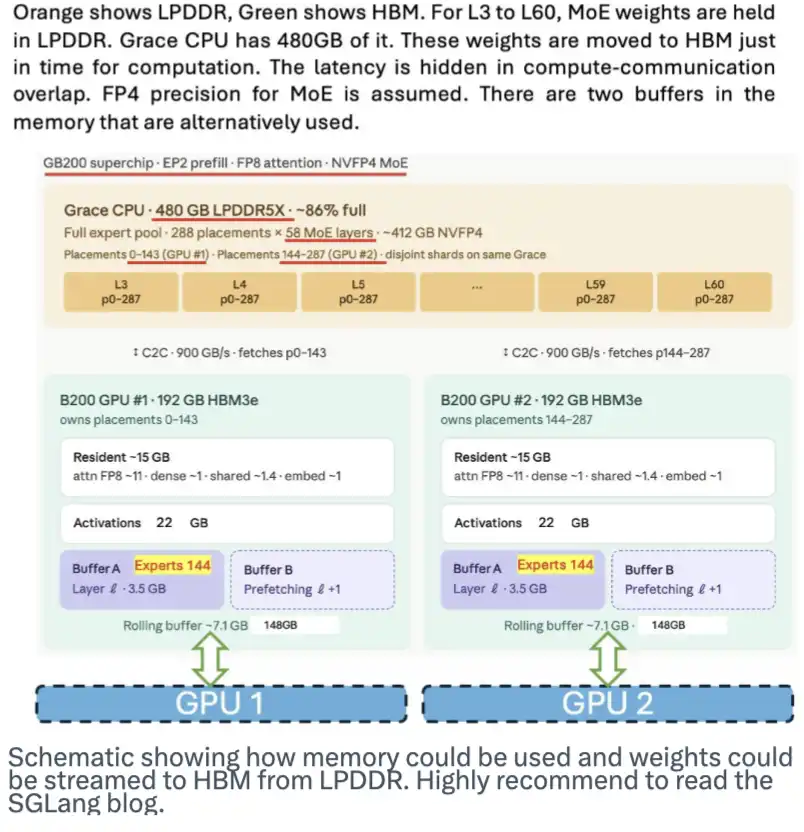
This diagram shows how memory could be used and how model weights could be streamed from LPDDR to HBM. I highly recommend reading SGLang's blog post.
When this innovation is combined with an extremely compact and lossless KV Cache, it will significantly reduce the demand for HBM.
So, who in China is producing LPDDR? The answer is CXMT (ChangXin Memory Technologies, Inc.), also known as ChangXin Memory. They are only about half a generation behind in LPDDR speed and one generation behind in density, which is not a significant gap.
In addition to an ample supply of NAND, the Chinese AI ecosystem will also have an abundant supply of LPDDR in the near future. Can this help alleviate the computing power pressure? The answer is: yes. Keep reading.

Intelligent Memory Usage Can Also Reduce GPU/ASIC Pressure
The use of NAND to store the KV Cache has a straightforward purpose: it allows the KV Cache to persist for a longer time, reducing the pressure on HBM, avoiding redundant KV Cache computation, thus lightening the computing burden on GPU and ASIC.
So, can LPDDR also play a similar role? In addition to serving as a storage location that can "on-demand instantaneously" stream weights to HBM, can it further reduce computing pressure?
The answer is: yes.
LPDDR can be used to store a large amount of content known as Engrams. In DeepSeek's Engram paper, they point out that MoE can scale model capacity through conditional computation, but the Transformer itself lacks a native "knowledge retrieval" mechanism. Therefore, Transformers often have to inefficiently simulate the retrieval process through computation.
To address this issue, DeepSeek proposed the Engram module. It modernizes the classical N-gram embedding into a hash-based O(1) lookup mechanism, creating a complementary sparse pathway, which they refer to as conditional memory.
This approach can save computation but also requires memory to accommodate the embedding table, which can be very large.
Essentially, this is a typical "memory-for-computation" trade-off. However, the key insight is that in terms of read cost per bit of data, the "memory" side is much cheaper—a single LPDDR lookup is far cheaper than having the data traverse through multiple Transformer layers for a forward pass computation. Therefore, in large-scale scenarios, this is a very cost-effective exchange.
This is how DeepSeek opts to sacrifice some memory to save on computation.
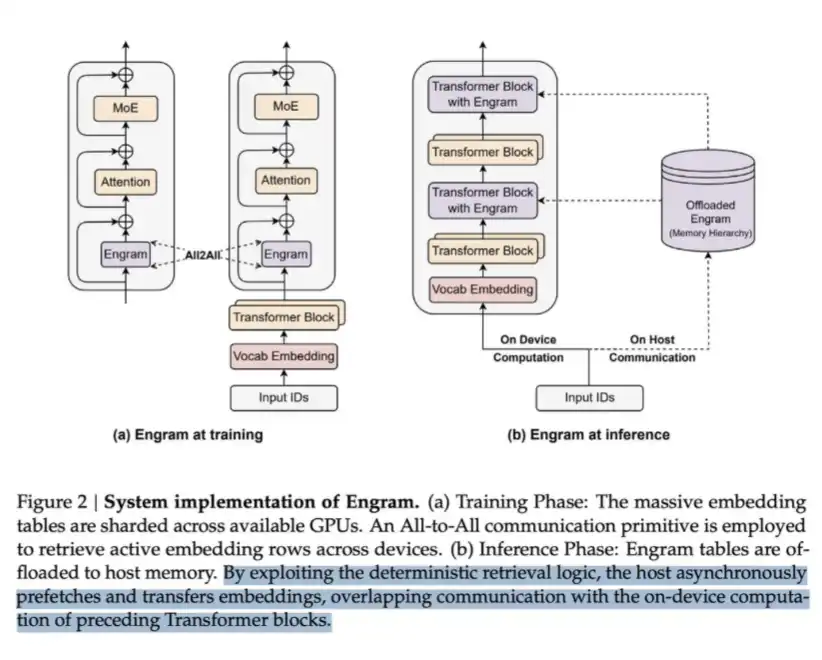
Trade-offs Worth Making
Due to the lack of equivalent transistor density and EUV, Chinese GPUs and ASICs are likely to lag behind Western GPUs in raw FLOPs performance in the long term. They also still have a significant gap in advanced packaging. Therefore, such trade-offs are very much worth making, especially given China's ability to mass-produce NAND and LPDDR memory.
Reviewing DeepSeek's Long-Term Strategy
From these innovations, DeepSeek's goal does not seem to be making a quick profit of a few billion dollars. Many of the choices it has made in the past point to this: there is still no multimodal system, no speech model, and definitely no video model.
What it is truly engaged in is a patient, long-term game that could reach a scale of $10 trillion: driving the formation of an alternative AI hardware ecosystem.
This is not only to make Chinese memory manufacturers key players in the Chinese and global AI hardware market but also to fundamentally reduce resource requirements, making AI model training and services more cost-effective. This way, many GPU and ASIC manufacturers, as well as network chipmakers, have the opportunity to become viable options.
At the same time, these innovations will also benefit the Western open-source ecosystem and the next generation of hardware manufacturers.
All the signs are already there. Let's take a detailed look back at these innovations proposed by DeepSeek so far:
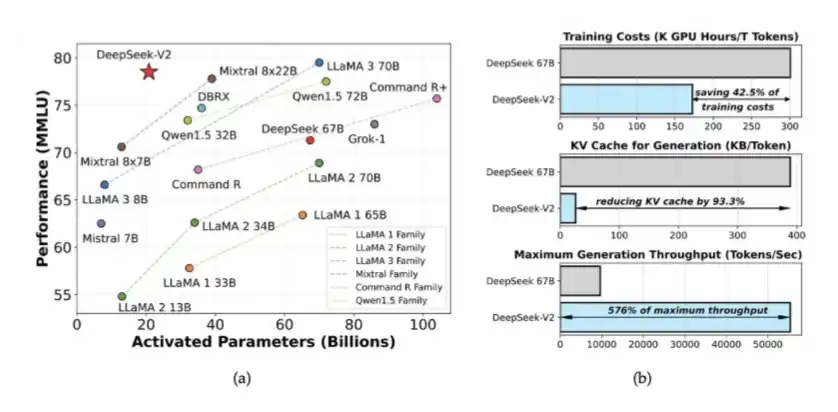
1. Expert Mixed Models (MoE) and MLA Introduced in DeepSeek V2
In V2, DeepSeek introduced MoE and MLA. MoE reduced the computational requirement for training high-intelligence models by about 40% to 50%; MLA reduced the KV Cache by 90%.
This made unloading the KV Cache onto SSDs quite efficient.
These ideas first appeared in DeepSeek's DeepSeek V2 paper released in May 2024. Later on, they laid the foundation for the training of DeepSeek V3. At that time, DeepSeek trained a system with performance close to that of closed-source models using only 2048 slightly degraded H800 GPUs.
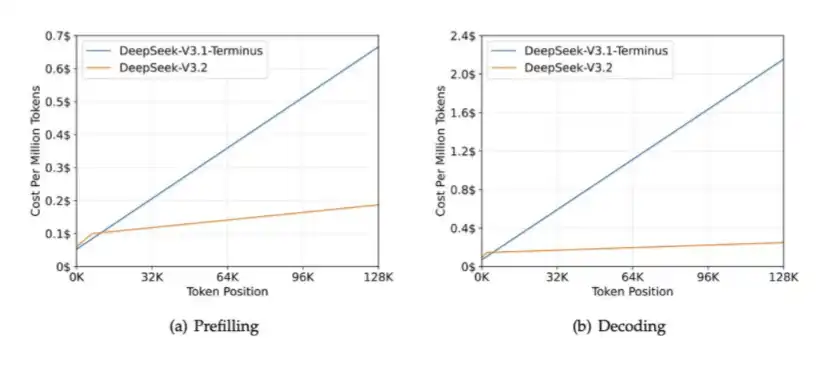
2. DSA: Introduced in DeepSeek V3.2 Exp, DSA is used to reduce the computational cost in long-context scenarios and alleviate HBM bandwidth pressure.
The core function of DSA is to ensure that the computational workload does not continue to grow as the context length increases. The chart below illustrates this: as the context length increases, the processing time of DeepSeek-V3.2 remains relatively stable.
3. mHC: Proposed by DeepSeek in December 2025 in the paper "mHC: Manifold-Constrained Hyper-Connections."
mHC is an innovation at the macro architecture level in DeepSeek, redefining the way information flows between Transformer layers.
In the past, starting from ResNet, models have commonly used standard residual connections, i.e., x + F(x). However, mHC extends the residual flow into multiple parallel information channels and allows the model to perform learnable mixing across these channels. The key is to constrain the mixing matrix to be a doubly stochastic matrix, achieved by projecting through Sinkhorn-Knopp to restrict it to the Birkhoff polytope. This mathematically guarantees that no matter how deep the model stacks, the signal magnitude remains stable.
This addresses the catastrophic instability issue faced by unconstrained Hyper-Connections in the past. Hyper-Connections were originally proposed by ByteDance, but without constraints, signal amplification would skyrocket to 3000x at a scale of 27 billion parameters, ultimately leading to complete training failure.
The computational cost of mHC is low: it only introduces approximately 6.7% actual training time overhead because it does not change the FLOPs of the attention or FFN layers, but only alters how the outputs of these layers are routed between layers.
However, the performance improvement is quite significant: at a scale of 27 billion parameters, mHC achieves a 7.2-point improvement on the BIG-Bench Hard inference task, a 3.2-point improvement on DROP, a 2.8-point improvement on GSM8K mathematical tasks, and a 1.4-point improvement on MMLU general knowledge tasks. And all these improvements are achieved at the same model scale and almost the same computational budget.
Essentially, mHC achieves higher per-parameter intelligence by providing the network with a richer and more expressive cross-layer information routing topology, almost without adding extra FLOPs.
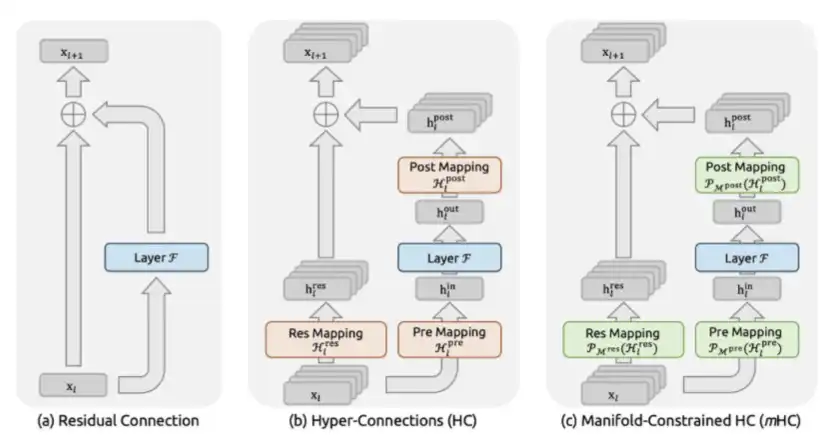
mHC is a complex architectural design, but it can bring a more stable training process and higher per-parameter intelligence.
4. CSA, HSA: DeepSeek was introduced in V4 in April 2026.
The goal of CSA and HSA is to further reduce the KV Cache requirement by 90% through KV Token compression, while significantly reducing the required FLOPs, thereby alleviating the pressure on HBM, GPU, and ASIC simultaneously.
5. Engram: DeepSeek was introduced in the first quarter of 2026, essentially using memory, specifically LPDDR memory, to exchange for computational efficiency to some extent.
As shown in the detailed chart below, with the same total parameter budget, Engram has brought a significant performance improvement.
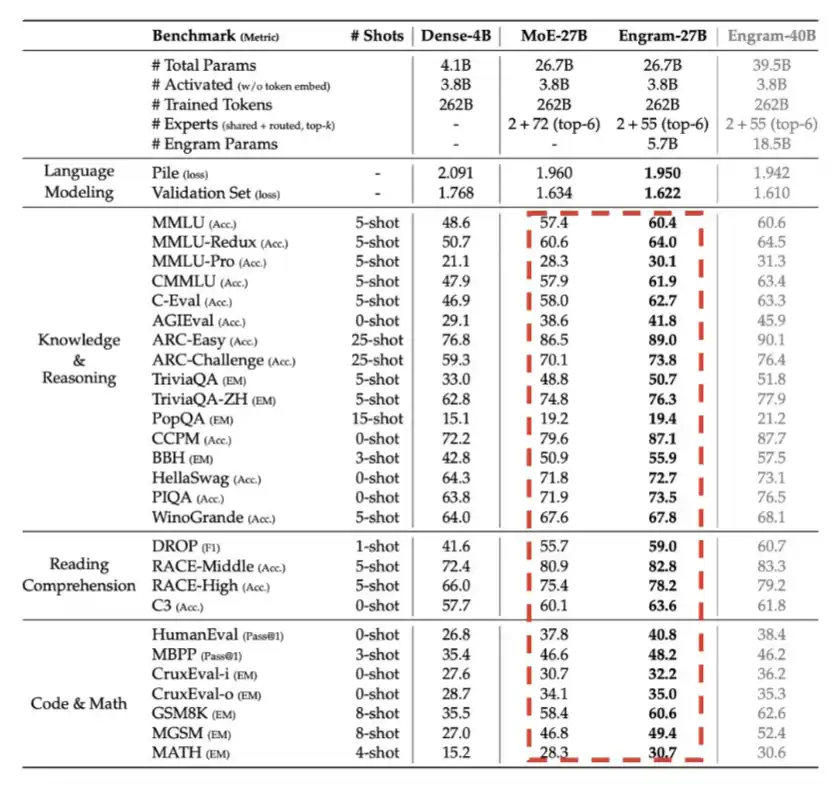
6. Engram: DeepSeek was introduced in the first quarter of 2026, essentially using memory, specifically LPDDR memory, to exchange for computational efficiency to some extent.
As shown in the detailed chart below, with the same total parameter budget, Engram has brought a significant performance improvement.

This is the advice DeepSeek shared with hardware vendors in the V4 paper. I am sure that in offline communications, the feedback they received will only be more.
7. The investment in TileLang also points in the same direction: DeepSeek is not only addressing its own computing bottlenecks but also driving the Chinese hardware ecosystem to compete with the Western ecosystem's capabilities.
With TileLang, developers can write a kernel only once, which is the underlying code for computation, and then successfully run it on multiple hardware platforms, provided that these platforms already have corresponding TileLang backend support.
I expect that other Chinese AI labs will also join one after another. This will help Chinese hardware vendors indirectly address the so-called "CUDA moat." At the same time, it will unlock more potential of Western hardware, such as AMD.
It is worth noting that many AI hardware platforms in China have already provided CUDA compatibility or a CUDA translation layer. For example, MooreThread, Muxi, Biren, and Tiensense are Chinese chip manufacturers with high CUDA compatibility through a translation layer. Therefore, theoretically speaking, they may not necessarily need TileLang.

Large-Scale Reinforcement Learning and RSI
As DeepSeek gains more computing power, meaning more optional hardware choices, and the model itself requires less computing resources, it can drive more ambitious training projects, particularly post-reinforcement learning training.
Reinforcement learning requires generating a large number of trajectories, which means generating trillions of tokens. This process will quickly become extremely expensive. Furthermore, if you want to train a model with a context length of 1 million, you need to generate trajectories of the same length. Only by training the model on such ultra-long trajectories can you truly support long-term tasks.
In addition, with the increase in hardware options, DeepSeek will have access to more hardware resources, driving research automation, namely RSI. RSI refers to AI designing and conducting experiments on its own. This approach will involve a lot of trial and error, and costs will rise rapidly. However, RSI is crucial for exploring the entire model design space. Before moving towards AGI and subsequently towards ASI, DeepSeek must have RSI capabilities.
What DeepSeek is doing today, the entire industry will follow tomorrow
DeepSeek's innovations focusing on expert hybrid models, MLA, DSA, and other directions have been successively adopted by global and Chinese AI labs.
For example, the development team of the GLM series model, ZAI, has used MLA and DSA. Kimi, also known as Moonshot, has adopted MLA and openly stated that its architecture is based on the DeepSeek design. Conversely, DeepSeek uses the Muon optimizer, which was originally used by Kimi (Moonshot) in large-scale training.
It is worth noting:
MoE was originally proposed by Google in 2017, with Noam Shazeer being a key author. DeepSeek's contribution lies in the large-scale application of MoE and the invention of its own complementary techniques.
Muon, short for MomentUm Orthogonalized by Newton-Schulz optimizer, was proposed by machine learning researcher Keller Jordan in late 2024. The Kimi (Moonshot) team was the first to use it for large-scale training.
But What About the Money?
Let's take a look at an interesting example from OpenAI.
OpenAI secured options/warrants to purchase AMD and Cerebras stock at a lower price, tied to milestones in their computational power consumption. For AMD and Cerebras, this was a very savvy deal because once OpenAI commits to using their hardware, their long-term success is significantly bolstered.
In AMD's announcement, it stated:
"As part of the agreement, to further align strategic interests of both parties, AMD issued warrants to OpenAI for the purchase of up to 160 million shares of AMD common stock, vesting upon the achievement of specific milestones. The initial tranche will vest upon completion of the initial 1-gigawatt deployment, with subsequent tranches vesting as the procurement scales to 6 gigawatts. The vesting conditions are also tied to specific stock price targets for AMD and technical and commercial milestones achieved by OpenAI to enable large-scale deployment by AMD."

I anticipate that DeepSeek will also enter into similar agreements with several Chinese memory, ASIC, CPU, and networking technology stack manufacturers, engaging in deep collaborations to enhance these manufacturers' hardware stacks for leading AI workloads.
Considering that the total market capitalization of AI stocks in all Western countries, including East Asian allies, has far exceeded $10 trillion, this method of "equity returns through collaboration" will enable DeepSeek to help China build an equally massive industry, carve out its own slice of the pie, and ultimately achieve its own $1 trillion valuation.
This approach will not only allow DeepSeek to earn far more money than traditional application subscription businesses but also fulfill its goal of "democratizing AGI." Liang Wenfeng is a loyal follower of Jim Simons and a smart enough capital player to not miss out on this opportunity.
If you look back at everything DeepSeek has done to date, this is the only explanation that makes sense.
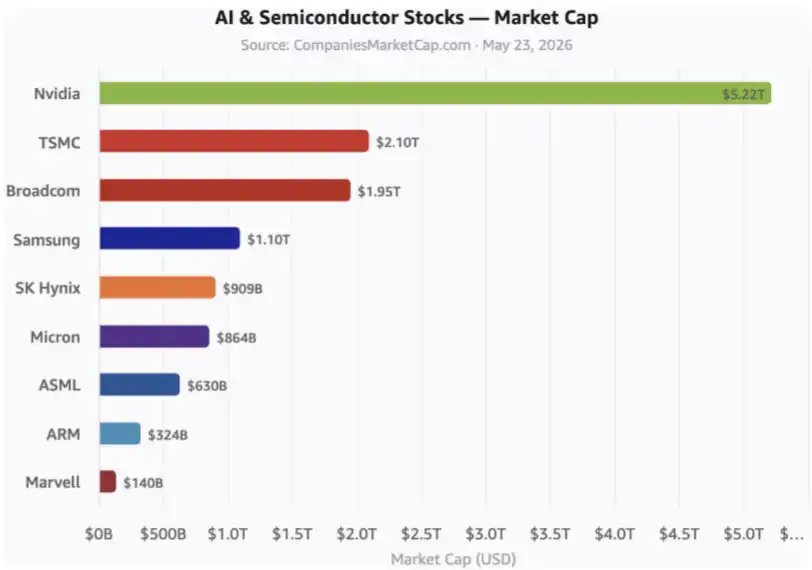
These are key AI stocks. The graphic does not include hyperscalers, which are large-scale cloud providers, and many other related companies.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia






