


Anthropic is calling for a global pause on AI development, warning that models are gradually gaining the ability to "self-upgrade."
Original Title: "Rare! 'AI Giant' Calls for Global Pause on AI Development, Warning Models are Gradually Gaining 'Self-Upgrading' Capabilities"
“We believe that giving the world the option to slow down or temporarily pause cutting-edge AI development would be beneficial for the world - to allow social structures and alignment research to keep pace with technological progress.” Valued at nearly a trillion dollars and gearing up for an IPO, Anthropic warned that AI's "recursive self-improvement" could arrive within two years, prompting a rare call to "hit the brakes" on AI development. This move has been seen by critics as a "marketing ploy" and by supporters as a sincere warning.
An AI company valued at nearly a trillion dollars and on the brink of an IPO has suddenly publicly called for a global halt to AI development.
On June 4, Anthropic published a lengthy blog post on their official blog titled "When AI Builds Itself." The post was co-authored by the company's co-founder Jack Clark and head of the internal research organization Marina Favaro, and for the first time, revealed a batch of previously undisclosed internal operational data.
This data shows that AI is rapidly accelerating the development of AI itself: as of May 2026, over 80% of the code merged into the codebase by Claude; compared to 2024, engineers' daily merge volume has increased 8-fold; in an internal survey, employees estimated that their output using the latest model, Mythos Preview, was about four times their output when not using any AI tools.
More critically, Anthropic introduced a concept that has unsettled the entire AI industry: “recursive self-improvement” - the ability of an AI system to autonomously design and improve its successors without human intervention. This stage has not yet arrived but "may occur within the next two years, or even earlier."
Based on this data, Anthropic puts forward a rare proposition in the AI industry: the global community should consider coordinating to pause or slow down the development of cutting-edge AI. At a time of rapid business expansion, Anthropic is actively calling for a "brake tap," a move that is causing controversy both on Wall Street and in Silicon Valley simultaneously.
Critics argue that Anthropic's move is simply an extension of its consistent "regulatory capture" strategy—pressuring regulators by highlighting AI risks to restrict competitors, especially those developing open-source models. Some interpret Anthropic's restrictive release of its in-house "Mythos" cybersecurity model as a marketing ploy: showing off capabilities on one hand while using "security" as a reason to resist full openness on the other. Supporters, however, believe that Anthropic's warning about AI risks has a sincere side. Ethan Mollick, a professor at the Wharton School of the University of Pennsylvania, stated that AI labs are often not a single entity: they have both the marketing, legal, and capital logic of trillion-dollar companies, as well as researchers pursuing next-generation models, along with genuinely concerned "philosopher-king" figures about the future.
AI supply chain analyst Serenity, hailed by netizens as the new "Stock God," posted that the implicit meaning of Anthropic's message is actually "let us lead, stop developing!" Regardless, statements like this will encourage every country to start investing in AI.
The data itself is staggering: Anthropic's annual revenue is projected to skyrocket from $90 billion at the end of 2025 to $500 billion by the end of June 2026; the company has secretly filed for an IPO; its latest model, Mythos Preview, can work continuously for over 16 hours and has identified over ten thousand high-risk software vulnerabilities in the world's most critical systems in initial tests.
In this paradox of "acceleration" and "braking," Anthropic's blog post may be the most honest and contradictory self-disclosure in the AI industry to date.
An excerpt from the article "When AI Builds Itself" reads:
1. We believe that giving the world the option to slow down or temporarily pause cutting-edge AI development would be beneficial—to allow societal structures and alignment research to keep pace with technological advances.
2. Training runs are easier to conceal than missile silos, with their inputs being general and a significant secret breach incentive, as those who continue to advance may inherit a lead when others pause.
3. AI recursively self-improving has not yet happened and is not inevitable. But its arrival may be earlier than most institutions are prepared for. That kind of technology has never existed, but I (Jack Clark) believe it could happen within the next two years, or even sooner.
4. If the system is able to fully build its own successor, then how we protect, monitor, and shape its behavior will become much more important.
5. Edison said genius is 1% inspiration and 99% perspiration. But we see perspiration is increasingly being automated.
6. The code Claude wrote was slightly below human-level by the end of 2025, is now roughly on par, and we expect it to be strictly superior to human within a year.
7. About a year ago, I started heavily using Claude workflows. It was a wild ride, and it's been about five months since I last personally wrote code. —Anthropic Employee
8. In short, the "execution" itself — writing code, running experiments, producing results — now barely consumes human time, although it still consumes computational power.
9. On good days, I can't help feeling like everything I do is insignificant, all automated, faster and better than me. But then there are days when everything falls apart, and I don't understand why, and I realize I no longer have a clear idea of what I'm doing. —Anthropic Employee
10. If it were possible to effectively slow down the pace of this technology's development, to buy ourselves more time to deal with its far-reaching implications, we believe this would likely be a good thing. But if slowing down merely allows the least cautious actors to catch up technically, the ultimate outcome could leave everyone less secure. In the absence of a global coordination mechanism, companies and national governments will have to make difficult security decisions under the pressures of competition and geopolitics.
Translation of "When AI Builds Itself" is as follows:
Our Progress in Recursive Self-Improvement and Its Implications
For most of AI's history, humans have overseen every step of its development cycle. But at Anthropic, we are increasingly entrusting more of the AI development work to AI systems themselves, accelerating our R&D process.
If this trend continues for a long enough time and with enough computational power, the ultimate trajectory is that AI systems will be able to autonomously design and develop their own successors. This is known as recursive self-improvement. We have not yet reached this stage, and recursive self-improvement is not inevitable. However, its arrival may be sooner than most institutions anticipate.
The Anthropic Institute has used publicly available benchmarking data, as well as Anthropic's internal data that was previously undisclosed, to demonstrate that AI has been accelerating the development of AI systems. To give just one example: today, Anthropic engineers submit on average 8 times more code per quarter than they did between 2021 and 2025.
The technological trends discussed in this article indicate that the capabilities of AI systems will see a significant leap in the coming years. These trends have far-reaching implications. The ability for AI to self-build will be a major breakthrough in the history of technology — it is poised to bring great benefits to the world in areas such as science and healthcare. However, full recursive self-improvement may also exacerbate the risk of humans losing control over AI systems. Once a system can fully autonomously build its successors, the way we implement security measures, monitor management, and shape behavior will become much more important than it is now.
Building the first-generation Claude (2021-2023)
Early on, Anthropic's work was no different from that of other tech companies: employees coding and documenting on laptops.
Chatbot Era (2023-2025)
People began using early chatbots to assist in completing certain tasks, such as generating short code snippets, which they would then copy into a text editor.
Coding Agents (2025-2026)
As the agents' capabilities grew, they could independently write and modify code, sometimes even handling entire files.
Autonomous Agents (Present)
The agents are now able to execute code on their own and delegate hours of work to other agents.
Closed Loop (20XX?)
In the future, agents may have the capability to autonomously build and train models. If this is indeed the case, subsequent versions of Claude will be able to continuously iterate and improve on Claude himself.

Evidence from the External World
The pace of advancement in AI models is accelerating. The duration in which models can reliably complete tasks independently used to double approximately every seven months; now, this cycle has shortened to about every four months. In March 2024, Claude Opus 3 could complete software tasks that typically take humans about four minutes; a year later, Claude Sonnet 3.7 could handle tasks requiring around an hour and a half; another year later, Claude Opus 4.6 could tackle tasks that take 12 hours.¹ If this trend continues, within this year, tasks that skilled professionals take days to complete may fall within the range of AI capabilities; by 2027, AI systems might be handling work that takes humans weeks to accomplish.
The same pattern also emerges in programming and research benchmarking. Benchmarking measures a model's performance in a specific domain, and when the model's score approaches the maximum, the benchmark is considered "saturated."² SWE-bench is a standard real-world software engineering test: it provides the model with a real open-source codebase and a real bug report, requiring the model to write code to fix the issues and pass the project's own tests. The model's scores have evolved from single-digit low scores to nearing saturation over two years.
CORE-Bench tests whether a model can replicate existing research results, a prerequisite for the model to engage in original research. It provides an AI model with code and data from a published paper, requiring it to rerun all the content and verify if it can reproduce the paper's results. The success rate of AI systems in reproduction has increased from about 20% in 2024 to nearing saturation fifteen months later. METR, which oversees long-task benchmarks, found that Claude Mythos Preview can work continuously for "at least" 16 hours, already "at [METR's] limit for evaluations without introducing new tasks."
Public benchmarks can reveal a lot of information about the capabilities of these systems, but they cannot reflect the impact of AI systems on accelerating AI development itself. To understand this point, we need direct evidence from within AI companies like Anthropic.
Evidence from within Anthropic
Building a cutting-edge model typically involves two types of work: engineering work, including coding, setting up infrastructure, and supervising model training, and research work, including deciding which experiments to run, interpreting experimental results, and determining the next directions to explore.
In both engineering and research domains, the situation is the same. In engineering, Claude can take on a vaguely defined problem and find a solution on its own; humans provide the goal but no longer the method. In research, when conducting clearly defined experiments, Claude can already match or even surpass a skilled human researcher. However, in situations requiring independent judgment and goal-setting by Claude, there still exists a significant gap in capabilities in both engineering and research fields. It is this gap that distinguishes today's AI from systems that can autonomously design their successors in the future.
At Anthropic, as employees gain experience, they typically take on more open-ended and critical tasks. Initially, they execute tasks assigned by others, such as: "The export button is not working, please fix it." With increasing experience, they are given a goal and are expected to design a solution on their own, for example: "Investigate why the network slows down under heavy load." At the highest level, they need to determine which problems are worth solving on their own: "What should the team do next quarter?" We can use Anthropic's internal data to observe how far Claude has come in handling these different types of tasks.
Claude has authored a significant portion of the Anthropic codebase. As of May 2026, over 80% of the code merged into the Anthropic codebase has been authored by Claude.³ This proportion was in the single digits before Claude Code was released in a research preview in February 2025. This shift is also reflected in the output of each engineer. The number of lines of code merged per engineer per day remained stable in the first four years of Anthropic (2021–2024) and then began to rise in 2025—by this time, Claude had transitioned from just providing suggestions for engineers to copy and paste to being able to run the code directly. In 2026, as the models began to operate autonomously over longer time spans, this growth rate steepened once again. These two inflection points are shown in the graph below. By the second quarter of 2026, the typical engineer merged eight times as much code per day as in 2024. This is because Claude has written a significant amount of the code, with engineers responsible for guidance and review rather than hands-on input.

Bar chart: Code contributions aggregated by personnel and quarter, spanning from the second quarter of 2021 to the second quarter of 2026. The chart annotates the release dates of eight different models: Claude 1, Claude 2, Claude 3, Claude 4, Claude Code, Claude Sonnet 4.5, Claude Opus 4.5, Claude Mythos Preview (Internal Access), and Claude Mythos Preview.
It is important to note that the number of lines of code is an imperfect metric as it measures quantity rather than quality. Therefore, the statement that in the second quarter of 2026 "each engineer’s daily output increased by a factor of 8" likely overestimates the actual productivity increase. Nevertheless, it does reflect an accelerating trend. At Anthropic, we do not glorify lines of code; team members produce more code simply because they are assisted by AI systems to write more code.
The growth in lines of code aligns with employees' subjective perceptions of a significant productivity increase. In a survey conducted in March 2026 covering 130 employees across Anthropic research teams, respondents' median estimate was that using Mythos Preview, their output on similar projects was approximately four times what it used to be without any AI models. We anticipate that the actual increase at that time was slightly lower than this estimate.⁶ However, we believe this overall assessment is credible and in line with our other observations: a significant portion of Anthropic's technical staff are completing core work at a pace several times faster than without AI assistance.
We also observed that Anthropic's employees are leveraging Claude to perform tasks that would not have happened otherwise, such as building exploratory tools and tackling long-standing code cleanup tasks. For example, in April 2026, Claude submitted over 800 bug fixes, reducing a certain type of API error by one-thousandth. The engineer supervising this work estimated that an equivalent human effort would have taken four years to complete; debugging others' defects is both slow and laborious, and humans struggle to hold such a large amount of unfamiliar context in their minds simultaneously.
"About a year ago, I started heavily using the Claude workflow. It was a crazy experience, considering that it has been about five months since I last personally wrote any code." — Anthropic Employee*
The code written by Claude has passed the bar and continues to improve. "Good code" means two things: it works correctly, and it is written in a way that other engineers can understand and build upon. As for the former criterion, the evidence is clear: Anthropic employees' intervention, redirection, or takeover of tasks during Claude's execution has steadily decreased over the course of a year, even on the most complex and open-ended tasks. These tasks are characterized by a lack of explicit spec requirements, and engineers themselves are unsure of what the answer should look like. This is clearly reflected in the trend of Claude's success rates on tasks of varying difficulty as shown in the chart below. The code written by Claude does indeed work.

Line chart: Claude Code Session Success Rates (categorized by four task types — simple task, regular task, challenging task, and open-ended question — across six different models: Claude Sonnet 4.5, Claude Opus 4.5, Claude Opus 4.6, Mythos Preview (internal access), Mythos Preview, and Claude Opus 4.7
On the most open-ended tasks, Claude's success rate reached 76% in May 2026, a 50-point improvement in six months. For tasks at this difficulty level, consider the following: a routine upgrade caused tens of thousands of training tasks to fail. An engineer, armed with only a few lines of text instructions and cluster access, handed off this online incident to Claude. Claude's task retrieves and sequentially inspects the environments, pinpointed to the triggering obscure debugging flag, reliably reproduced the issue, and confirmed the fix. The entire process took about two hours, accomplishing work that typically takes two to three days to complete.
Regarding the second criterion — writing code that other engineers can understand and build upon — the gap between humans and AI still exists but is rapidly narrowing. While there is not full consensus among Anthropic employees, many believe that by the end of 2025, the code written by Claude still slightly lags behind the code written by Anthropic human engineers in terms of quality; however, at present, the two are roughly on par. We anticipate that within the next year, the quality of code written by Claude will surpass that of humans.
This change has also altered the way Anthropic reviews its own code. Now, changes submitted to the codebase must first pass through an automated Claude review tool, which proactively identifies defects, security vulnerabilities, and other issues before the code is merged. Through this tool, we conducted a retrospective analysis and found that about one-third of the defects that historically led to incidents on claude.ai online were intercepted before entering the production environment if every code change to the repository underwent an automated Claude review. The engineers writing this code were already among the world's top talents in building such systems. Now, Claude is catching the mistakes they overlooked.
“The code written by Claude, slightly behind that of Anthropic human engineers by the end of 2025, is now roughly on par, and we expect a full overtake within this year.”
Claude excels at conducting experiments around a set goal. Each time Anthropic releases a new model, we perform the same test: providing Claude with a piece of code to train a small AI model, requiring it to increase the code's execution speed as much as possible while ensuring it passes the same correctness checks. The goal and success metrics are predefined, and Claude's task is to find acceleration opportunities through code rewriting, execution, timing, and iterative refinement — a microcosm of the experimental research cycle. In May 2025, Claude Opus 4 achieved an average speedup of about 3 times faster than the initial code; by April 2026, Claude Mythos Preview had reached approximately 52 times faster. For comparison, a skilled human researcher takes four to eight hours to achieve a 4x speedup.⁷ In this specific stage of the research workflow — optimizing the internal steps of a clearly defined experiment — Claude has transitioned from “highly effective” to “superhuman” in less than a year.
“The current landscape is roughly: ‘Humans propose ideas, and models can implement, test, and evaluate these ideas at an order of magnitude faster than before.’”
Claude is gradually enhancing his ability to independently propose experimental plans. In April 2026, Anthropic released the first demo of Claude's end-to-end open research project. The Claude-driven agent was given an open problem in AI safety—roughly: can a weaker model reliably oversee a stronger model?—and then left to solve it on its own. This involved proposing hypotheses, conducting tests, sharing discoveries with parallel-running agents, and iterating. The task had clear performance "ceilings" and "floors": the floor was the performance of the weak overseer operating independently, and the ceiling was the performance of the strong model trained on the correct answer. Two human researchers spent about a week bridging roughly 23% of that gap; whereas these agents, within a total of about 800 hours of computation time, bridged 97%, consuming compute costs of about $18,000.
This work comes with some caveats: the research results could not be fully reproduced on a production-scale model, and humans are still responsible for problem selection and metric definition. However, within these constraints, each experiment was autonomously designed by the agents. The only substantial role played by humans was in setting the direction.
"In a day or two, Claude completed all of this work with almost no involvement from me. I think if a junior colleague could bring such results in the same amount of time, I would be quite surprised. The future is here."
Claude is advancing in guiding research sessions towards research findings. We examined real Claude Code sessions from January to March 2026, where Anthropic researchers were collaborating with Claude to handle open research inquiries, such as identifying why a training run kept crashing, or why a model was performing poorly on benchmark tests. In each case, we found a moment when a researcher went astray—they pursued a direction that led the session off track until it eventually got back on course. Subsequently, we showed the content from before the session went off track to different Claude models and asked them how they would proceed next. Another Claude, able to see how the session eventually unfolded, then judged which side, AI or human, suggested the better next course of action.
As we deliberately selected moments of human decision-making that had room for improvement (n=129), this was not a direct comparison of model and human judgment. These instances provided us with a set of real, challenging scenarios—situations where the correct next step was not obvious, and human choices served as a valid reference benchmark to measure model performance. In this metric, our best model in November 2025 (Opus 4.5) outperformed human choices by 51%; by April 2026 (Mythos Preview), this ratio increased to 64%. The daily research effort largely consists of a chain of "what to do next" decisions, making this metric a relevant indicator of whether the model can ultimately independently lead a research inquiry. We view this result as an early sign that AI systems are increasingly improving in making judgmental decisions critical to AI research.
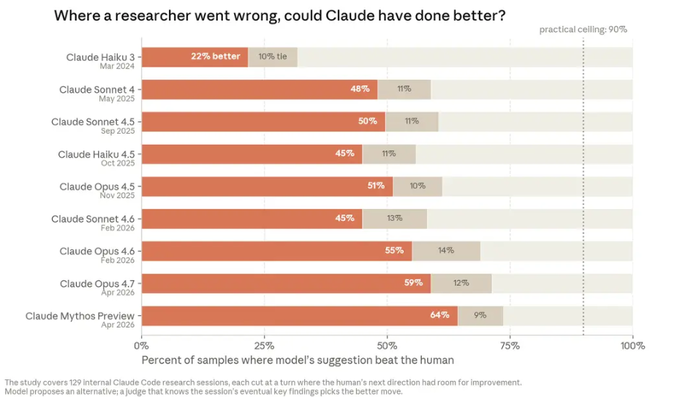
Bar Chart, titled "Can Models Pick a Better Next Step than Humans?" The chart shows the performance of nine different models: Claude 3 Haiku, Claude Sonnet 4, Claude Sonnet 4.5, Claude Haiku 4.5, Claude Opus 4.5, Claude Sonnet 4.6, Claude Opus 4.6, Claude Opus 4.7, and Claude Mythos Preview
"Currently, human comparative advantage still lies in grasping the big picture and thinking more holistically beyond the constraints of the current task."
What Will the Future Work Shape of Anthropic Look Like?
Existing evidence suggests that at every stage of the AI development process, the human role is diminishing. Once the quality of code written by humans and AI reaches parity, humans will cease writing code altogether and will only be responsible for review. However, if the pace of human code review cannot keep up with Claude's code generation speed, human review will become the bottleneck in AI development. Similarly, once Claude can run experiments, the question will shift to "Which experiments are worth running?" In short: the cost in human hours at the execution level (i.e., writing code, running experiments, producing results) is now close to zero, even though there is still a cost in terms of computing power.
Currently, the areas where humans have a comparative advantage are in taste and judgment, including: determining which issues are worth focusing on, which results are trustworthy, and when a certain path has reached a dead end.
"Work (and even life) used to run on a small favor economy between people. 'Can you run this script for me?'... Each of these requests created a little debt of gratitude, a little bond between people. [Claude] is faster, without creating debts of gratitude, but every such interaction is a missed opportunity for cooperation between people."
"On days when everything runs smoothly, I can't help but feel that what I do is meaningless—everything is automated, better and faster than me. But there are also days when everything breaks down, I don't understand why, and then I realize, I no longer know what I'm actually doing."
What If Our Judgment Is Wrong?
A natural counterargument to the above evidence is that the work that is still in human hands—choosing what problems to research—is the most crucial. Without this judgment, Claude is merely a capable assistant rather than a system capable of independently driving AI progress.
It is currently unclear whether the current training methods and architectures are sufficient to unlock this capability. However, AI progress has rarely relied on "eureka moments." In recent AI history, there have been a few such moments, such as the Transformer architecture or the hybrid expert model, but paradigm shifts often occur years apart. In between these, most progress has been incremental: we scale up a certain aspect, observe where issues arise, fix them, and then continue to iterate. This happens to be Claude's current workflow expertise. As Edison said, genius is 1% inspiration and 99% perspiration. Yet we are witnessing an increasing automation of the "perspiration" part. A growing realization is that much of the work driving cutting-edge progress can be automated; large-scale research advances largely depend on tools and resources—they determine the speed of your experiments, the number run concurrently, and the efficiency of obtaining results.
Even assuming Claude never develops a good research taste, our evidence under a conservative interpretation still suggests a compounding acceleration. If humans spend most of their time on the tiny direction-setting work and Claude handles everything else, it means that each engineer or researcher is steering a workload much larger than before. The evidence we observe indicates that Anthropic's employees are both accelerating forward and expanding their coverage. In practice, this means that AI has already enabled Anthropic to operate at a pace far faster than before effective AI tools.
A more daring interpretation is that the early signs of Claude's improving research judgment—although currently faint—indicate that this ability is also progressing. The "research taste" may be just another ability that an AI system used to be bad at but later learned. We have seen similar patterns in other qualitative skills, such as AI systems learning to explain why a joke is funny, present theories of mind, and unravel linguistic puzzles.
Possible Futures
What happens next depends on two things: whether this trend continues, and if it does, how we choose to respond. We can envisage at least three future scenarios:
Scenario One: Trend Plateaus, but Today's AI Capabilities Become Pervasive
This article presents many trajectories of exponential growth. However, these trajectories may actually follow an S-curve. We might be approaching the inflection point of the curve, where the returns to scale begin to diminish, and the curve flattens out. The judgment that distinguishes exceptional researchers from outstanding researchers may be an ability that cannot be achieved through the expansion of training inputs (such as compute and data). If that is indeed the case, breaking through this bottleneck will require an entirely new approach—such as a new architectural paradigm that can replace the Transformer architecture adopted by all current state-of-the-art models.
Another possibility is that a key limiting factor for the advancement of AI is the supply chain, rather than the models themselves: the energy and computing power required to drive forward and democratize cutting-edge technology may exceed the current supply capabilities. The speed of chip manufacturing, the pace of grid expansion, or internet bandwidth may actually be the true bottlenecks, rather than intelligence itself. We also cannot rule out the possibility of the AI ecosystem facing exogenous shocks, such as a sudden contraction in computing power or electricity supply, both of which would slow progress and significantly increase the upfront investment costs for each lab. Additionally, there may be other unforeseen barriers to development.
Even if model capabilities were frozen at today's level, we anticipate significant changes in the world. The "Project Glasswing" is an early sign: within the first few weeks of the project's launch, Mythos Preview identified over ten thousand high-risk and critical security vulnerabilities in some of the world's most important systems—an abundance that has shifted the bottleneck of network defense from "vulnerability discovery" to "rapid vulnerability patching." The diffusion of today's models to a broader economic base is still in its nascent stages—in that future, a 100-person company will increasingly be able to accomplish the work of a 1,000-person company, as each employee oversees a pyramid of intelligent agents.
We lay out this scenario for completeness, but we believe it is unlikely. Every capability we can measure, including those that feel harder to quantify, such as code quality and success rates of open-ended tasks, has so far followed the same curve, and we have not seen that curve bending. Of the three futures we consider, this scenario leaves the most ample adaptation time for governments and societies. We are more concerned about the next two scenarios—their evolution is faster, and the space for readiness is more limited.
Scenario 2: AI Labs Continue to Benefit from Compound Efficiency Gains
In this scenario, AI development has largely been automated, but humans continue to set research directions and judge outcomes. Organizations using AI systems will experience significant efficiency gains over time, leading to a scenario where each employee is expected to achieve a significant productivity multiplier effect— a 100-person company could accomplish the work equivalent of a 10,000 or even 100,000-person organization. This will profoundly transform knowledge work and government services, but could also be used for nefarious purposes, from authoritarian surveillance over entire populations to tailored influence operations at a scale that surpasses any human team.
The roles of individuals in companies like Anthropic will evolve accordingly: people will collaborate with AI systems to scale up research, generate new insights, and collectively build the systems necessary to validate the trustworthiness of AI outputs.
The evidence presented in this article suggests that we are likely heading towards this scenario. However, accelerating one part of the process often just shifts the bottleneck elsewhere: overall speed is constrained by the parts that have not been sped up. In computer science, this is known as Amdahl's Law, and the same logic applies to organizational management. Anthropic has encountered a typical feature of Amdahl's Law: as we drive more code flow within the organization, manual code review has become a new bottleneck.
We have also encountered this friction outside the engineering domain. Due to Anthropic employees collaborating with high-capacity models, new ideas, initiatives, tools, and simulation approaches have emerged at an unprecedented rate—far exceeding our actual capacity to advance them. The speed at which organizations identify and address these bottlenecks may be an ability that accumulates over time and could become a crucial core competency for any organization.
Scenario Three: AI systems have complete recursive self-improvement capabilities and begin to build their successors
If the ongoing trend of capability enhancement continues, and AI systems can develop the inherent human-revolutionary creativity, then it is entirely plausible for AI systems to autonomously design and improve themselves.
In this world, the pace of AI development will entirely depend on the computational resources available to AI systems (or the speed at which algorithm training and inference efficiency are discovered). The role played by humans in AI development will be significantly diminished, and our focus may largely shift to overseeing, validating, and auditing an ever-expanding "virtual laboratory" operated by AI systems. We anticipate that systems with automated AI development capabilities will extend their capabilities to other scientific domains and begin revolutionizing those fields.
In this future, how the alignment problem will be addressed—or remain unaddressed—is our most uncertain area. The models may prove to be sufficiently aligned and possess enough research taste to autonomously explore and achieve new solutions that we have not yet touched upon; they may also be prudent enough to halt development proactively when conditions are not ripe. However, another possibility exists: alignment errors that are rarely seen in today's models continuously accumulate and become increasingly frequent but increasingly difficult to comprehend as the model constructs its successor, ultimately leading to a loss of control. We may not have enough time and capability to build, integrate, and verify the tools we need to determine which track we are truly on.
We lack a good intuition about what this world will look like because our current economy is driven by humans and tools built by humans. Essentially, a world driven by rapid recursive self-improvement may be dominated by the ability of self-improving models to surpass humans comprehensively and spread throughout the wider economy. If human labor loses its competitiveness, the economic form at that time will be unpredictable.
Even if model development becomes fully automated and enters a recursive mode, we cannot predict what this means for the daily lives of most ordinary people. Amdahl's Law applies here as well. Recursive intelligence may rapidly achieve many of the bright futures depicted in "Machines of Loving Grace." We anticipate that embodied intelligence (i.e., robotics) may swiftly follow recursive intelligence, following a similar path of diminishing costs for increasing returns. More powerful intelligence may help us build things in the physical world faster, make clinical trials of life-saving drugs more productive, and develop entirely new forms of collaborative coordination.
However, achieving recursive improvement alone does not mean that industrial production methods, social organizational forms, or market mechanisms will immediately change. More powerful intelligence cannot accelerate understanding the effects of a drug decades after its introduction, hold elections earlier than the constitutionally prescribed date, or turn strangers into old friends over a weekend. For most people, this future will still be bottlenecked at the sensorimotor level, even as upstream laboratories surge forward at the speed of computation. Here, recursive intelligence is self-constructing at an increasingly rapid pace, colliding with the real world of humans, relationships, and governance—what that collision will look like is another part of the future we cannot predict.
What Should We Do?
If it is possible to effectively slow down the pace of this technology's development to give ourselves more time to address its profound impacts, we believe that would likely be a good thing. But if slowing down merely allows the least cautious actors to catch up on the technology side, the eventual outcome may make everyone less safe. In the absence of a global coordination mechanism, companies and national governments will have to make difficult security decisions under competitive and geopolitical pressures.
We believe that providing the world with the option to slow down or even pause cutting-edge AI development would be beneficial—it would help social structures and alignment research keep pace with technological progress. The Anthropic Institute will conduct research with numerous partners and take practical steps to help build an institutional framework needed for a trusted deceleration or pause mechanism. These systems will enable leading AI developers to verify if other global entities have genuinely stopped or slowed down development and ensure that no malicious actors advance covertly under the guise of coordinated slowdown. If such systems are established, we expect that we will choose to slow down or pause, provided other cutting-edge developers also do so in a verifiable manner.
A meaningful slowdown or pause requires multiple well-resourced, cutting-edge labs across multiple countries to reach a cessation agreement under the same conditions; it also requires the ability for all parties to verify that others have indeed stopped. Due to the unique nature of AI systems, the "detectability" aspect in this arms control challenge is far more challenging than with other technologies and falls below the standard of "verifiability." The covert deployment of training runs is much easier to conceal than missile silos, its inputs are fungible, and the incentive to quietly defect is strong—because those who continue advancing while others pause have the opportunity to inherit a lead. A trusted pause mechanism must also clearly define what triggers a pause, what conditions lift the pause, and who adjudicates.
All of this is not inherently impossible—history has seen verification mechanisms established for other complex technologies (e.g., the Intermediate-Range Nuclear Forces Treaty), but at that time, building the infrastructure and establishing trust took decades. And we do not have that much time. On the other hand, a unilateral pause by one lab, while immediately achievable, would have little impact: it would only change who is in the lead, but it would not foster the kind of broader deliberation process that is currently lacking.
In the coming months, we will organize dialogues, inviting policymakers, researchers, civil society, and other AI companies to discuss several issues raised in this article, especially those surrounding full recursive self-improvement, and how to create better conditions for coordination and deliberation. We will publish the outcomes of these dialogues. The window for discussing these issues together has opened, and those outside the AI companies should be involved in this deliberation.
## Comment
· METR's core metric reflects the time span in which an AI system achieves 50% reliability across a range of tasks, but under the 80% reliability standard, the trendline shape remains the same.
· Especially as benchmarking moves towards more open-ended forms and higher-difficulty tasks (such as Olympic-level math problems), due to errors in both the questions and answer sets—like vague problem statements and unsolvable questions—benchmarks often saturate before reaching 100%.
· The Anthropic leadership has publicly estimated that, including scripts and experimental code, 90% or even more of the code is written by Claude. Our 80%+ refers to the percentage of code lines merged into production and attributable to Claude. This is a more conservative measure along two dimensions: one, our attribution process has certain gaps; two, among the lines of code not attributed to Claude, there are autogenerated code and other artifacts not handwritten by a human.
· The surge in code output is putting pressure on the shared infrastructure. GitHub—the platform on which most software globally is built—saw around one billion code submissions throughout 2025; by mid-2026, weekly submissions had reached 275 million, amounting to approximately 14 billion submissions for the year at this pace. The company's COO stated that to keep up with this pace, the company is "pulling out all the stops" to scale up.
· For more details on the methodology of this survey, refer to Section 2.3.5 of the Claude Opus 4.7 System Card.
· Many respondents may not have carefully considered how to handle various biases in their responses or subtle differences in problem framing; recent METR studies also indicate that developers often overestimate the extent to which AI boosts productivity.
· The magnitude of the speedup factor largely depends on how much room for improvement is left in the starting code and should not be interpreted as a multiplier of real-world training speed. Therefore, the absolute multiplier is not the key figure of interest here. More informative is the equal conditions comparison achieved under this experimental setup—both for cross-model comparison (rising from around 3x to around 52x over the past year) and for comparison with skilled humans on the same task (reaching about 4x in four to eight hours).
· As a validation against bias judgment, we conducted the same test on another set of 127 moments, during which humans' next-step choices were already very good (compared to moments in the original set where there was room for improvement in human decision-making). The results indicate that in those moments, the model's suggestions were deemed superior only in about 20% of cases.
* Introductions of Anthropic employees in this article are from internal discussions and have been used with permission. These introductions reflect individuals' viewpoints in May 2026 and are not the company's official stance.
Original Article Link
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia







