


Karpathy joins Anthropic – What does it mean for AI?
Original Title: What Karpathy Joining Anthropic Actually Means For Claude
Original Author: @nateherk
Translation: Peggy, BlockBeats
Editor's Note: Andrej Karpathy joining Anthropic is not just a "renowned AI expert joining a leading lab" personnel news. What is more worth noting is the shift in product direction indicated by this personnel change.
Over the past year, the focus of the AI industry's competition has still largely centered around the models themselves: whose benchmark is higher, whose inference capability is stronger, who is leading in the rankings. However, as the product capabilities such as Claude Code, Skills, MCP, project memories, Agent workflows continue to improve, a clearer trend is emerging: the model itself is just one layer of the product, and what truly determines user output efficiency is the context, memory, workflow, skills, connectors, file structure, style guide, and goal loops that surround the model.
The "context engineering" that Karpathy has repeatedly emphasized in the past few months aligns perfectly with this change. What truly determines whether AI can generate stable value is not just the prompt the user writes, but whether the model can understand your documents, workflows, style standards, business goals, and decision-making system. In other words, the next stage of AI competition may no longer be just about "whose model is stronger," but about who can better integrate the model into real work scenarios.
From LLM Wiki to AutoResearch, and to goal-driven cycles like /goal, the direction Karpathy has openly explored has always revolved around the same question: how to transform AI from a "chat window that answers questions" into a working system that can understand context, perform tasks continuously, and iterate around goals. The recent layout of Anthropic in Claude Code, enterprise services, ecosystem connectors, and workflow capabilities is also unfolding along the same path.
Therefore, Karpathy's joining Anthropic is not just a talent move, but more like a punctuation mark on Anthropic's product roadmap: the future of AI tools lies not only in the model parameters but also in the data, workflow, memory systems, and industry knowledge that users accumulate. Whoever can organize these contexts may truly move AI from being a "tool" to being "infrastructure."
The original article is as follows:
A few hours ago, Andrej Karpathy made a post announcing his decision to join Anthropic.
The simplest version of this story is: an AI luminary has joined a major AI lab.
But the more interesting questions are: Why Anthropic? And why now?
Because if you look back at what Karpathy has been openly building for the past few months, and then at the features Claude Code has been rolling out relentlessly, you'll see that the two seem to have been converging towards a common product direction for quite some time.
Background
Karpathy is one of the most influential figures in modern AI.
He was one of the founding members of OpenAI in 2015, spent five years leading AI at Tesla, returned to OpenAI in 2023, left a year later, and then founded his own AI education company, Eureka Labs. He also launched LLM 101n, a free course that teaches users how to build a language model from scratch.
He is also the originator of the concept of "vibe coding": you simply describe in English what you want, let AI write the code, and then continuously feel, guide, and iterate. He also introduced the concept of "context engineering," which will be a key part of the discussion later in this article.
So, this is not just a regular hire. It signifies one of the most influential voices in the AI field joining one of the most momentum-driven AI labs today.
Claude Code has already become a preferred tool for many builders when creating agents, coding, or working with real-world knowledge. About a week ago, Ramp released its AI Index. According to this data, Anthropic has now surpassed OpenAI for the first time in enterprise adoption: 34.4% to 32.3%.
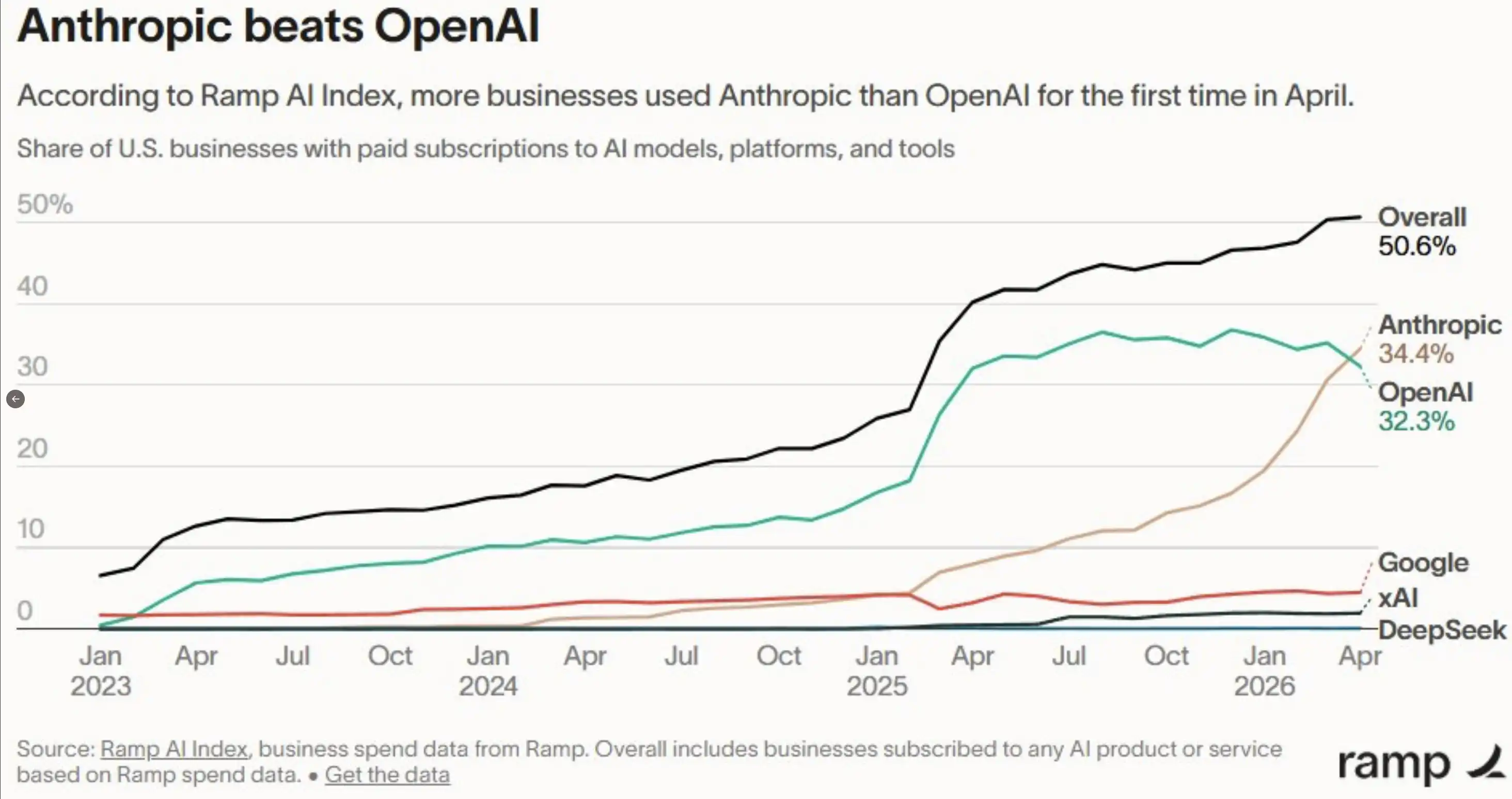
Of course, it's fair to say this is just data within Ramp's customer base. OpenAI still has a strong consumer brand and numerous enterprise contracts not captured in this sample. I don't want to overplay this, but this signal is indeed hard to ignore.
Earlier this month, Anthropic also announced the establishment of a new enterprise AI services company. This is a joint venture formed by Anthropic, Blackstone, Hellman & Friedman, and Goldman Sachs, aimed at helping mid-sized enterprises integrate Claude into their core business processes.
Take another look at this move: they are working on the model, as well as on product entry points, such as Claude Code, Skills, MCP; they are building a partner network; and now they have added another layer of service capability to help enterprises truly bring the product to fruition.
This is no longer a game of "here's a model, now figure it out yourself."
Wrapper Is the Product
Today, most discussions about AI still treat the model itself as the complete product: which model won on which benchmark, who is stronger between Opus 4.7, GPT-5.5, Gemini, how the rankings have changed.
The model is certainly important—I'm not saying the model is not important. But the longer these tools are used, the more obvious it becomes: the model is just one layer of the product. What truly changes what you produce daily is the layer outside the model, the wrapper.
That is also why two people using the same model can end up with completely different results.
The so-called wrapper is everything that determines how the model is used.
→ Claude Code itself, Codex, Skills, Subagents, Hooks, MCP connector.
→ Your CLAUDE.md, your memory, your documentation, your use cases.
→ Your file structure, your style guide, and your true definition of "good output."
This is the environment in which the model operates.
If you open a brand-new chat window with no context at all and ask it to help you solve a business problem, it knows nothing about you and can only guess. So, you find yourself explaining the background you've already mentioned ten times in the conversation.
But if you give it your documents, use cases, workflows, style guides, and real success criteria, the same model will produce completely different results.
This is exactly where Karpathy aligns with Anthropic. The reason he introduced "context engineering" instead of continuing to focus on prompt engineering is because of this. The truly important ability is not to write a perfect prompt but to build the right environment for the model to truly function and to remember and use context across different sessions.
Anthropic has been quietly building this environment. Karpathy has been openly teaching this approach. Now, these two sets of ideas have merged into one company.
Once this is understood, what Karpathy has been publicly doing in the past few months no longer seems like a set of random projects, but more like a roadmap.
LLM Wiki and Your Data Moat
In April of this year, Karpathy released the LLM Wiki. This project quickly gained traction on X.
Its structure is very simple. If you want to learn more, I've also done a full YouTube tutorial
→ a raw/ folder, containing numerous markdown files, which can be notes, sources, transcripts, or any material.
→ a wiki/ folder, where the Agent synthesizes all content, establishes connections between materials, and generates a mind map.
→ a schema document, like CLAUDE.md or AGENTS.md, to tell the Agent how the system operates and how to absorb new material.
It's not about letting AI search through original files or simply running a vector query; it's about letting AI build a living, ever-evolving knowledge base. It reads the material and understands the relationships between them. Many people have started using it to build their own "second brain."
This is more important than it appears on the surface. When many people say "data is a moat," what comes to mind is a massive corporate database. But for the average builder, the real moat is smaller and more practical.
It could be your meeting notes, internal SOPs, customer call records, transcripts, your commonly used naming conventions, and those frameworks that truly belong to your work.
If Claude can transform this content into a model-visible, usable context, then for you, this model will become smarter and more useful every week.
This is the lock-in effect. Not because you can't switch models, of course, you can switch. But the longer you continue to build context, workflows, and memories in a tool, the harder it becomes to leave over time.
LLM Wiki is not just a side project. It's a clue. I wouldn't be surprised to see more native versions of similar functionality in future iterations of Claude Code or the Claude project memory. You can already see some hints in the auto-dream feature.
Of course, you don't have to wait. This weekend, you can roll up your sleeves and have Claude Code read your important documents and build a wiki in this way.
If you want to be AI-first, your data is only truly valuable when the Agent knows how to find it and how to use it correctly.
AutoResearch and /Goal Loop
In March of this year, Karpathy released a project called AutoResearch. It is an automated research loop. If you've played Ralph Loop, you'll find that the two are somewhat similar in concept.
The pattern is roughly:
1. Get a training script.
2. Propose a modification.
3. Run a short training task.
4. Check the results based on objective metrics: pass or fail.
5. Repeat continuously until the goal is achieved.
To be honest, AutoResearch is not a feature I personally use frequently. I don't train models or build applications that require this type of loop. But its form is essential.
Define the goal. Let the Agent work. Come back after completion.
Look at what the entire ecosystem has recently launched: Codex now has /goal, Hermes has /goal, and Claude Code also has its native /goal.
I'm not saying Karpathy personally invented this feature. I don't know. And from a fundamental perspective, AutoResearch and /goal are not the same. But their patterns are clearly related.
Both are taking us out of the "one prompt, one response" mode.
They are pushing us towards another form of interaction: setting the outcome, letting the Agent decide how to proceed, and then coming back when the conditions are met.
This is an enhanced vibe coding. Define "what you want," don't define "how to do it," and then wait for it to be completed.
Once this pattern is combined with the LLM Wiki concept, the whole thing no longer resembles a chatbot. It starts to resemble a real employee: understanding your business and working continuously towards a goal until it is achieved.
The Education Thread
In Karpathy's announcement of joining, there is a sentence worth magnifying. He said, "I remain deeply passionate about education."
Eureka Labs, his previous company, is essentially an education project. Its goal is not to teach people to "click this button, connect these nodes," but to help individuals truly understand AI from within: how these systems actually operate.
A rare quality in Karpathy is his ability to explain highly technical things in a way that feels understandable and approachable. Understanding something is one skill. Teaching it to others in a way they can truly use is a completely different skill.
This is crucial for Anthropic. If the next stage of competition revolves around context, workflows, skills, memory, and loops, then the bottleneck is not just technology but also education.
A recent IBM study on AI adoption and transformation management clearly demonstrates the significant gap between companies being "AI-capable" and "truly leveraging AI." Most companies get stuck at this point.
Bringing in someone highly skilled in AI education to the organization to help bridge this gap is by no means a small move.
Three Predictions for Claude Code
The following are mere predictions. I have no insider information and do not know Anthropic's roadmap. But based on Anthropic's recent product launches and Karpathy's publicly shared content over the past few months, the direction is quite clear.
Anthropic Will Build a "Context App Store"
They have already begun to do so. The foundation of official plugins, skills, and marketized components is taking shape.
But I'm not talking about a prompt marketplace.
I'm talking about a category of components: skills, workflows, project memory, vertical context, evaluation loops, and connectors that link to real data. This also includes examples that can teach a model what "good" looks like in a specific role.
By plugging these components into your domain, you can immediately extract higher value from the model, even if the model itself is already quite intelligent.
Because for the average user, the model itself is increasingly becoming less of a unique selling point. The real question is: who can build the right data and wrapper around the model to deliver results that truly bring ROI to the business.
LLM Wiki is a pattern of transforming messy information into usable memory.
/Goal is a pattern of translating goals into an automated loop.
Karpathy's educational work, on the other hand, is a pattern of making complex AI concepts accessible.
What he truly packaged is a way of behaving. If Anthropic could turn this way of behaving into a true ecosystem, Claude Code would no longer just be a programming tool but would become a marketplace.
More /Goal-style commands will appear in the product.
/Goal is likely just the first version, not the final form.
One can imagine many specialized versions in the future: research loops, debugging loops, wrap-up loops. There may also be commands optimized for specific verticals, where the Agent already knows what "done" means in those scenarios.
I don't know what they will ultimately be called, but that's not the point.
The point is that the interaction interface will change. You no longer say "do this step," but you start saying, "In this specific vertical scenario, keep going until this condition is met."
Anthropic will introduce an educational layer to help users package their workflows.
This is the boldest prediction. Honestly, it's also the one I find most interesting.
If Anthropic wants to establish a true context marketplace, ordinary people must also be able to participate in contributing, not just developers and researchers.
In other words, domain experts from regular professions should also be able to join.
→ Accountants who truly understand the month-end closing process.
→ Real estate operators who are familiar with every step of property entry.
→ YouTubers who know what good packaging is, what bad packaging is, and can complete a topic brainstorming from scratch.
This knowledge is very valuable. But for now, it's either stuck in people's heads or scattered across chaotic documents, Slack threads, and ClickUp channels.
You can already see similar beginnings in reality. Many coaches are starting to build their AI avatars and chatbots, charging users to interact with these AI entities. This is the manual version. People want to extract others' expertise and apply it to their own businesses.
If I were to build an Ad Agent today, I'd be stuck. Because I lack the domain expertise. But if there was a marketplace that allowed me to subscribe to high-quality SME context in a particular domain, I would become a customer instantly.
This is the layer I'll be focusing on next.
Conclusion
The real story is the pattern itself.
The model is just one layer. The wrapper outside the model is becoming the real product. Your data and workflow are becoming the real lock-in. What Karpathy has been teaching for the past few months is exactly this. What Anthropic has been doing for the past few months is also this.
So, this join is not a news headline, but a roadmap. I break down the entire logic in the full video, the link is in the first reply.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia






